Explained: Retrieval Augmented Generation (RAG)
A step-by-step explanation to understand how RAG works
In this guide, we will learn:
- What is Retrieval Augmented Generation (RAG)?
- How does RAG work?
Large language models (LLMs) are trained on vast amounts of data and have impressive generation capabilities. However, they lack context and cannot provide answers based on specific knowledge or facts. RAG is a way to provide additional context to LLM to generate more relevant responses. Let us try to understand this with an example:
** System Prompt **
You are a helpful AI assistant.
** User **
Where was I born?
** LLM **
I am sorry, I do not have that information.
Now, let's see how RAG can help in this situation.
** System Prompt **
You are a helpful AI assistant. Use the context provided below to generate a response.
Context: User was born in New York, USA.
** User **
Where was I born?
** LLM **
You were born in New York, USA.
This is a simple example of how, in RAG, we can provide additional context to LLMs to generate more relevant responses. It can be extended to provide context from a large database of personal data, facts, or any other information.
Let's dive deep into how RAG works.
Step #0
We cannot feed all of the information to the LLMs as is; they have limited context windows and can easily hallucinate. We need to provide the LLMs with a way to access the only relevant information when needed. This is where the vector store comes in.
Vectors and Embeddings
Vectors are a way to represent data using numbers used in machine learning, a powerful way to represent and manipulate data. In the context of RAG, we take the data and generate embeddings (vectors) for each piece of data. The core idea of embeddings is that semantically closer data points are closer in the vector space.
A typical vector embedding for a piece of data might look like this:
[-0.2, 0.5, 0.1, -0.3, 0.7, 0.2, -0.1, 0.4, 0.3, ...]
The length of a vector array is called its dimension. Higher dimensions allow the vector to store more information. Think of each number in the vector as representing a different feature of the data. For example, to describe a fruit, features like color, taste, and shape can each be represented as a number in the vector.
The choice and representation of these features form the art of creating embeddings. Effective embeddings capture the essence of the data compactly, ensuring that semantically similar data points have similar embeddings.
For instance, "apple" and "orange" are closer in the vector space than "apple" and "car" because they are semantically similar. They will appear closer in the vector space. Look at the image below to visualize this concept.
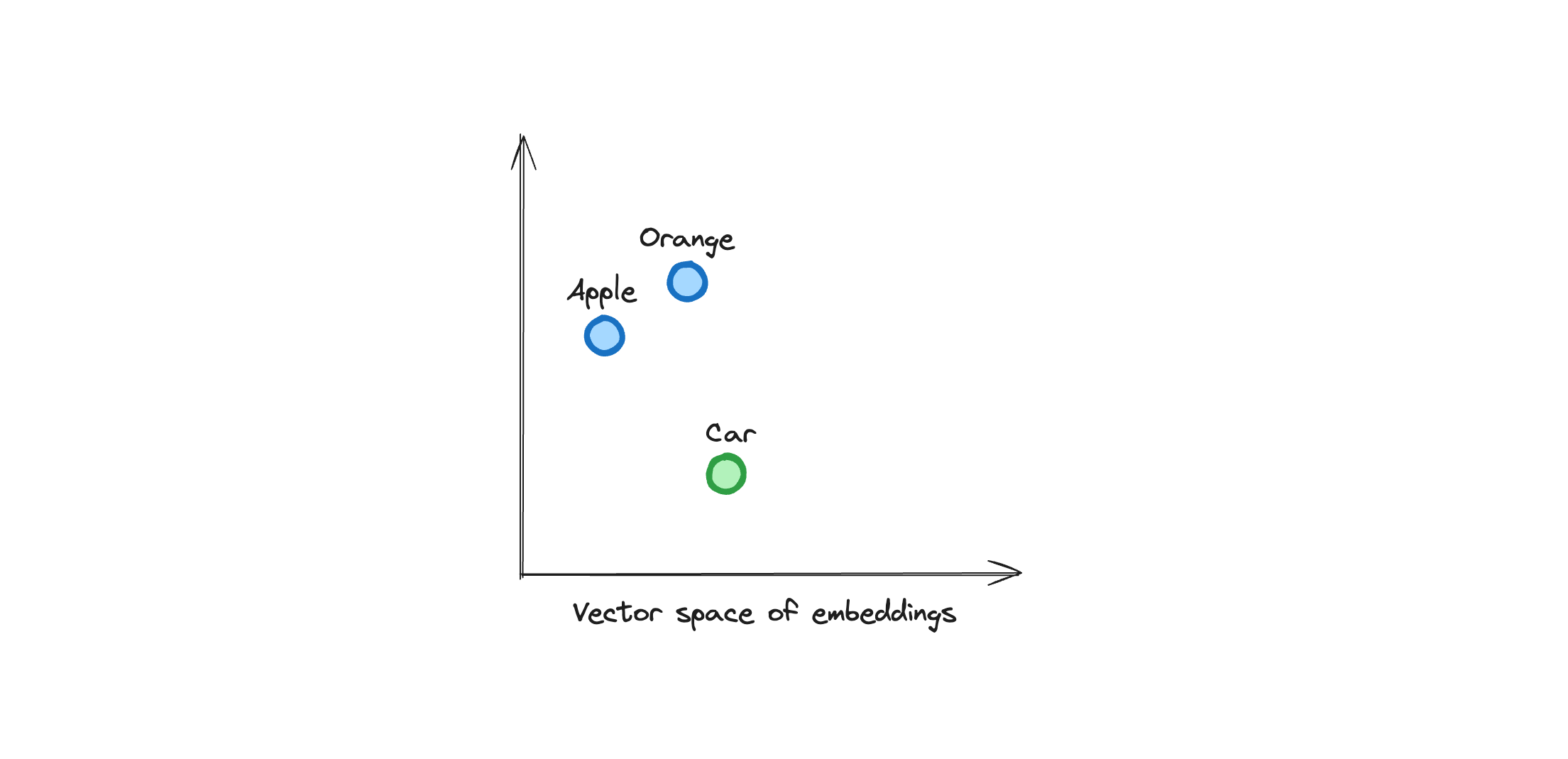
It can represent any kind of data, such as text, images, and audio. We embed this data into vectors and store them in a vector database. The goal is to store relevant information in the vector database and provide LLMs with a way to access it, known as retrieval. We will explore how to do this in the next steps.
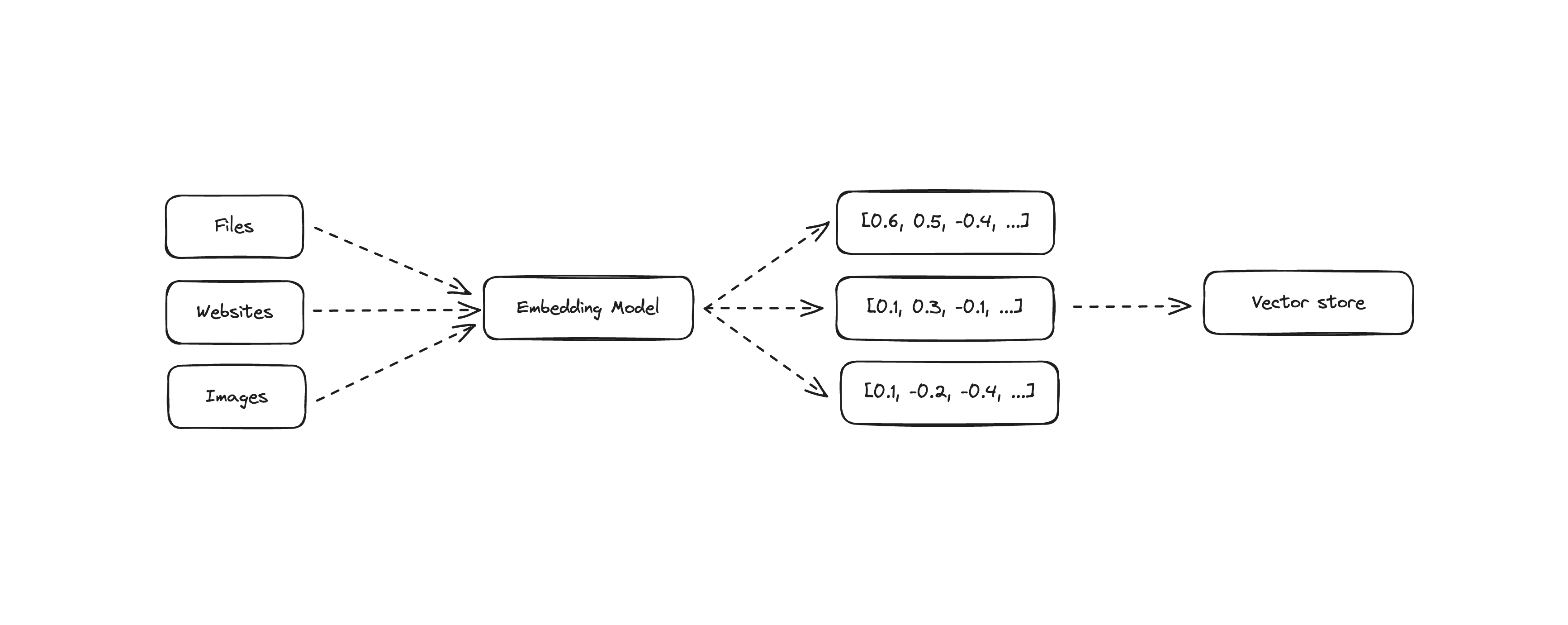
You get the idea, right? Don't worry if you don't, we will see how to do this in the next steps. Langbase takes care of all the heavy lifting for you with its memory sets.
Chunking
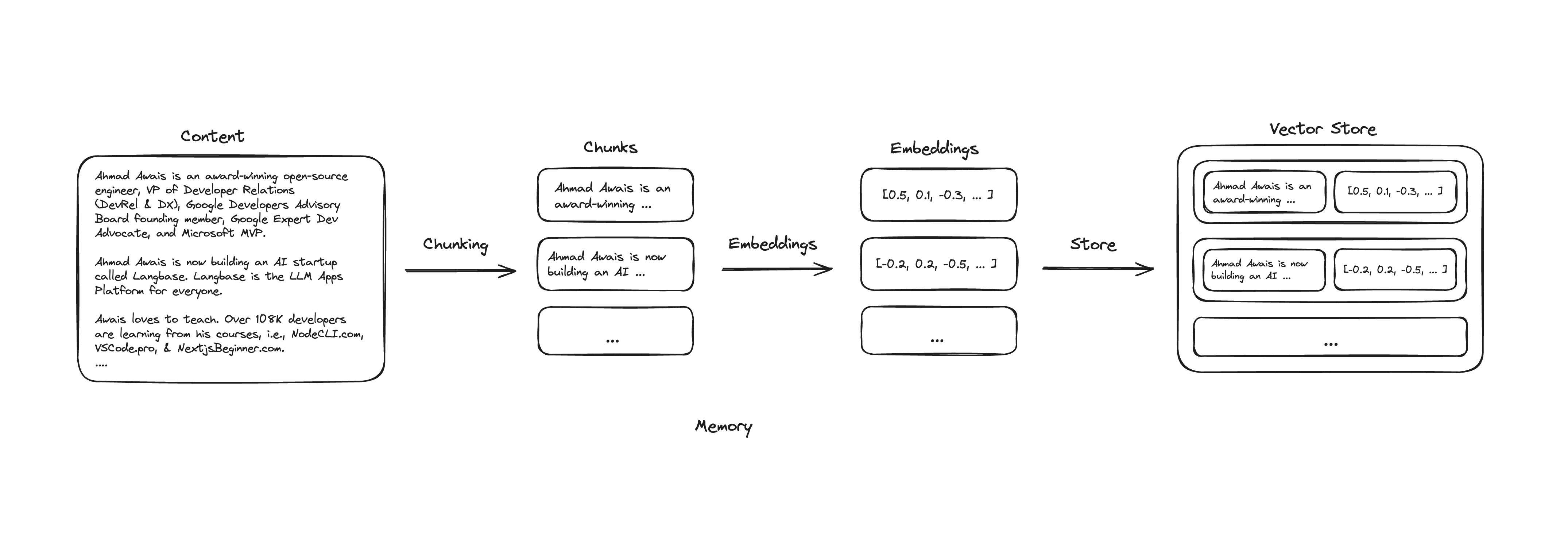
Files can be of any size. We cannot possibly capture the essence of the entire file in a single vector. We need to break down the file into smaller chunks and generate embeddings for each chunk. This process is called chunking.
For instance, consider a book: we can break it down into chapters, paragraphs, and topics, generating embeddings for each chunk. Each piece of information is represented by a vector, and similar pieces of information will have similar embeddings, thus being close in vector space.
This way, when we need to access information, we can retrieve only the relevant pieces instead of the entire file. Each piece has text and its associated embeddings. Together, these form a memory set, as shown below.
Step #1
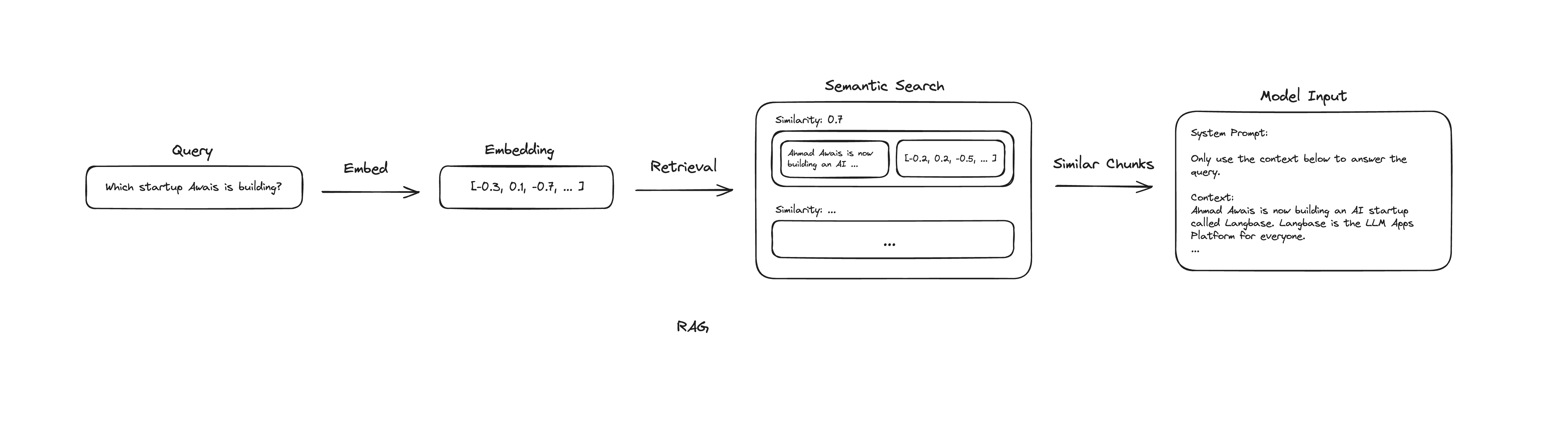
Now that we have the embeddings stored in the vector store, we can retrieve the relevant information when needed. This is called retrieval. When a user inputs a query, we do the following:
- Generate embeddings for the query.
- Retrieve the relevant embeddings from the vector store.
We generate embeddings for the query and compare them with the data embeddings in the vector store. By retrieving the closest, semantically similar embeddings, we can then access the associated text. This provides the relevant information to the LLMs.
Step #2
Now that we have the relevant information, we can augment the system prompt with this information and give instructions to the LLMs to generate a response based on this information. This is called augmentation. It is then passed to the LLMs to generate text based on this information.
Step #3
Generation is the final step where we provide the LLMs with the user input and the augmented information. The LLMs can now generate text based on this information. The generated text is more relevant and meaningful as it has the context of the relevant information.
Putting it all together, we have the following workflow:
- User inputs a query.
- Retrieve the relevant information from the vector store.
- Augment the system prompt with this information.
- Generate text based on the augmented prompt.
Langbase offers powerful primitives like Pipe and Memory to help you ship AI features and RAG applications in minutes. Check out our detailed guide on RAG to ship your first RAG application today!