Concepts
Using memory is fastest way to use your knowledge data with a Pipe to build a RAG system.
Let's understand the key concepts of Memory to successfully build a RAG system:
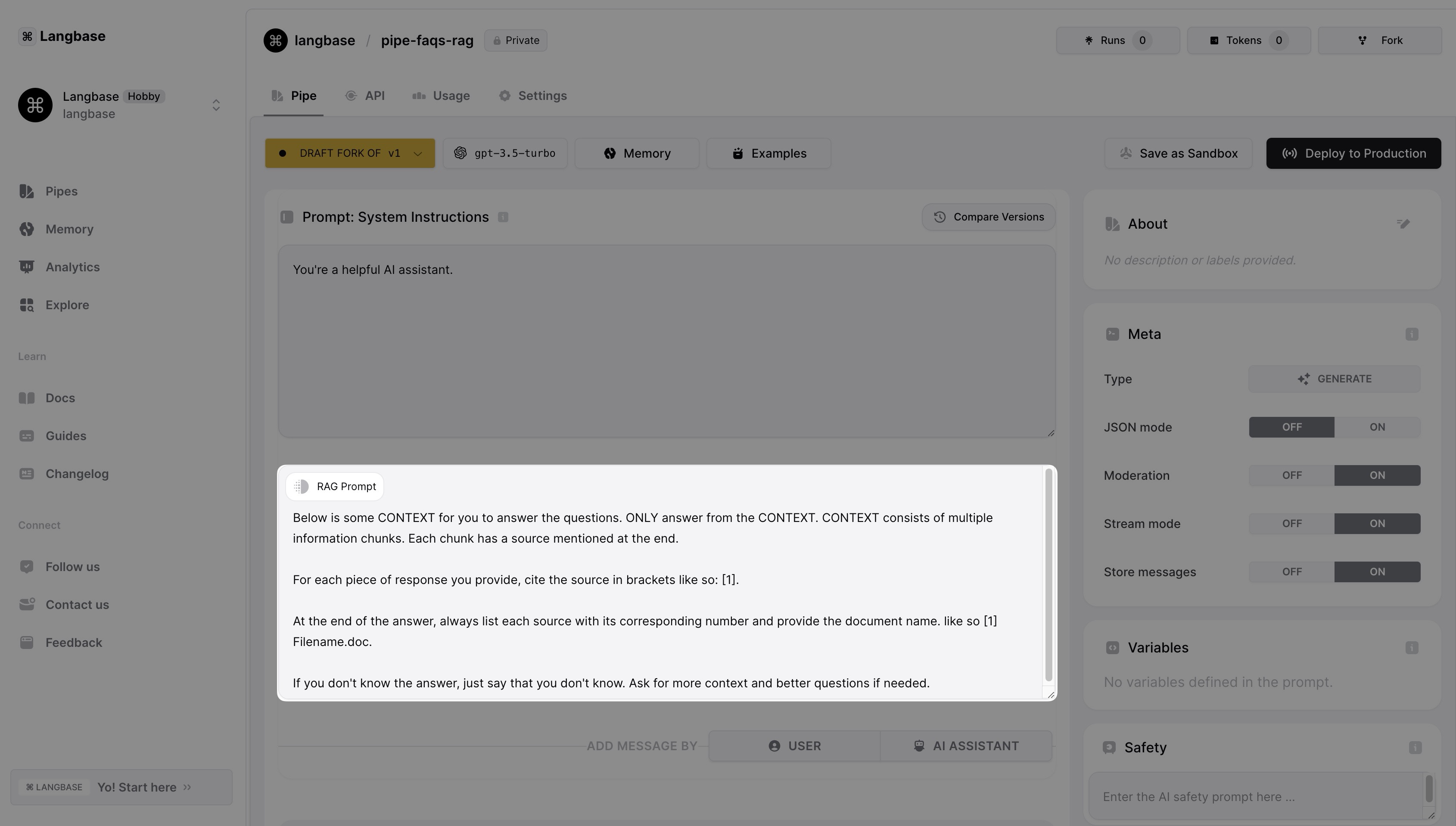
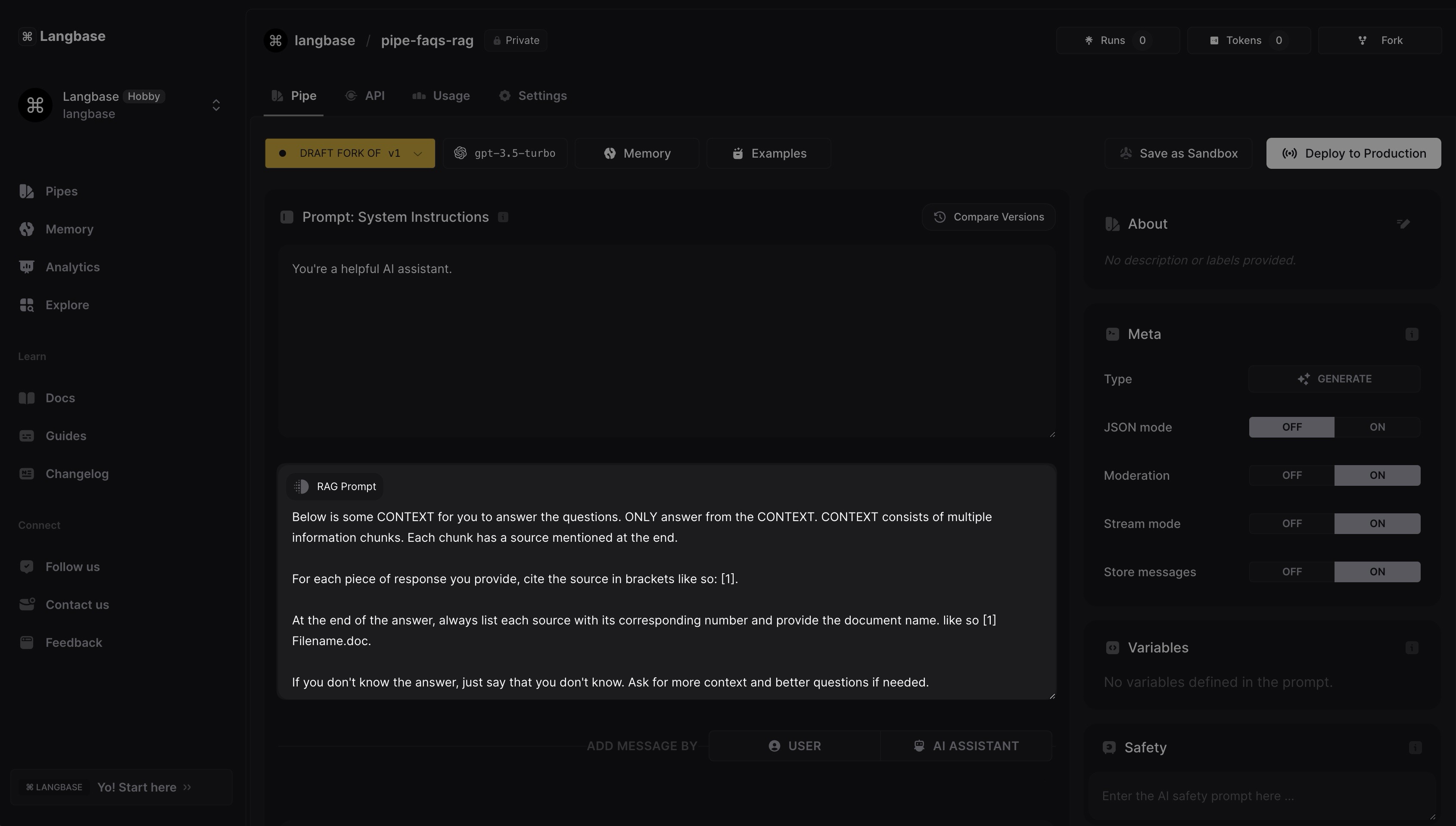
When a memory is attached to a Pipe, by default a RAG prompt appears which is fed to LLM to utilize the memory. The default prompt works fine in most cases, but you can customize the prompt based on your use case.
Once the document is uploaded, it is submitted to a queue for processing. The status is reflected in the memory page. You can "Refresh" the status to get the latest status of the document on the memory page. Below are the possible status of the document:
- Queued: Document is in the queue waiting to be processed
- Processing: Document is being processed
- Ready: Document is ready to be used
- Failed: Document processing failed due to some error
If the document processing fails or takes too long, you can re-upload the document to process it again. In case of failure, the error message can be seen by hovering over the "Failed" status. If the issue persists, please contact support.
Following are the steps involved in document processing:
- Chunking: The document is split into chunks. Each piece contains a certain piece of information. During the retrieval, only the relevant chunk is fed to LLM to generate the response.
- Embedding: Each chunk is converted into an embedding. Embeddings are used to find similar pieces of information during retrieval.
- Indexing: Embeddings are stored in vector store and indexed for faster retrieval.
Enabled
The Enabled/Disabled toggle button will include/exclude the document from the memory when the memory is used in a Pipe.
Before embedding the document, it is split into chunks and each chunk is then embedded. The chunking parameters can be adjusted to control the number of chunks generated from the document. The chunking parameters are:
- Chunk Max Length: The maximum number of characters per chunk. The chunk size can range from
1024to30000characters. We recommend a small chunk size so vector representation can capture distinctive information in each piece. - Chunks Overlap: The number of characters by which the chunks overlap. The minimum overlap is
256characters. It helps in tracking chunk boundaries and managing document flow.
The default chunking parameters are set to Chunk Max Length: 10000 and Chunks Overlap: 2048. Chunking settings can be adjusted based on the document size and the use case.
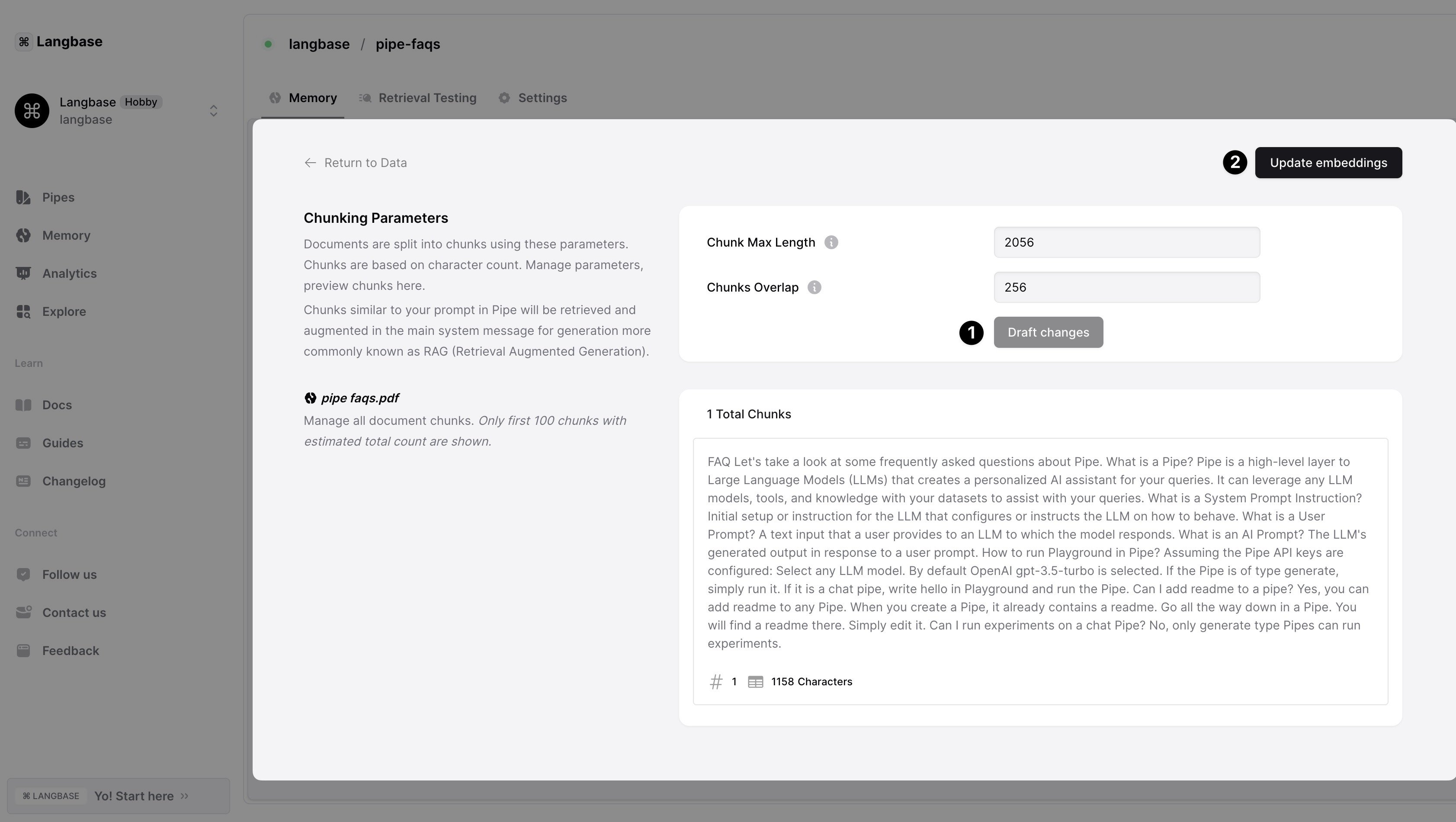
To change the chunking settings, click on the document name on the memory. The document details page will open where you can adjust the chunking parameters. Below is how you can adjust the chunking parameters:
-
Change the
Chunk Max LengthandChunks Overlapvalues and click on theDraft changesbutton. This will only preview the chunks: it will not embed and save the changes. -
If you are satisfied with the preview, click on the
Update Embeddingsbutton to save the changes. The document will be submitted for re-processing with the new chunking parameters. Embeddings can be only updated once the chunks are drafted.
During the chunking, another parameter called Separator is used to split the document into chunks. By default ["\n\n", "\n"] are used as separators to split the document into chunks based on paragraphs and lines. So, if a separator is found in the document, the document is split into chunks at that point as it takes precedence over the chunking parameters. Soon, you will be able to customize the separator based on your document structure.
Embeddings are the vector representation of the document. All documents in a memory are converted into embeddings. These embeddings are used to find similar documents during retrieval testing.
By default, OpenAI's latest embedding model text-embedding-3-large with 256 dimensions is used to generate embeddings.
Embeddings are a way to represent text in a way that captures the meaning of the text. The embeddings are generated in such a way that similar texts have similar embeddings. This allows us to find similar texts by comparing their embeddings.
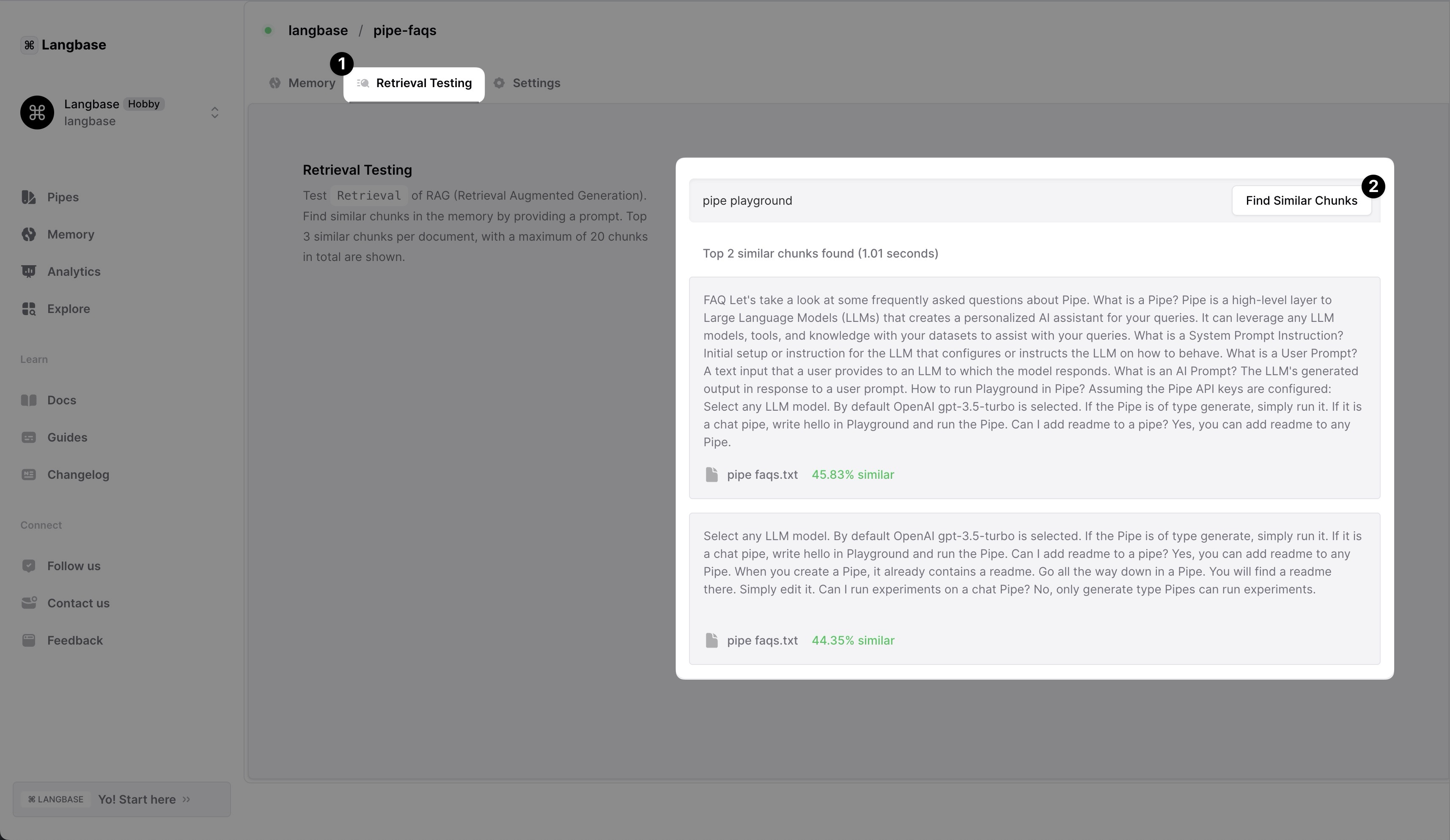
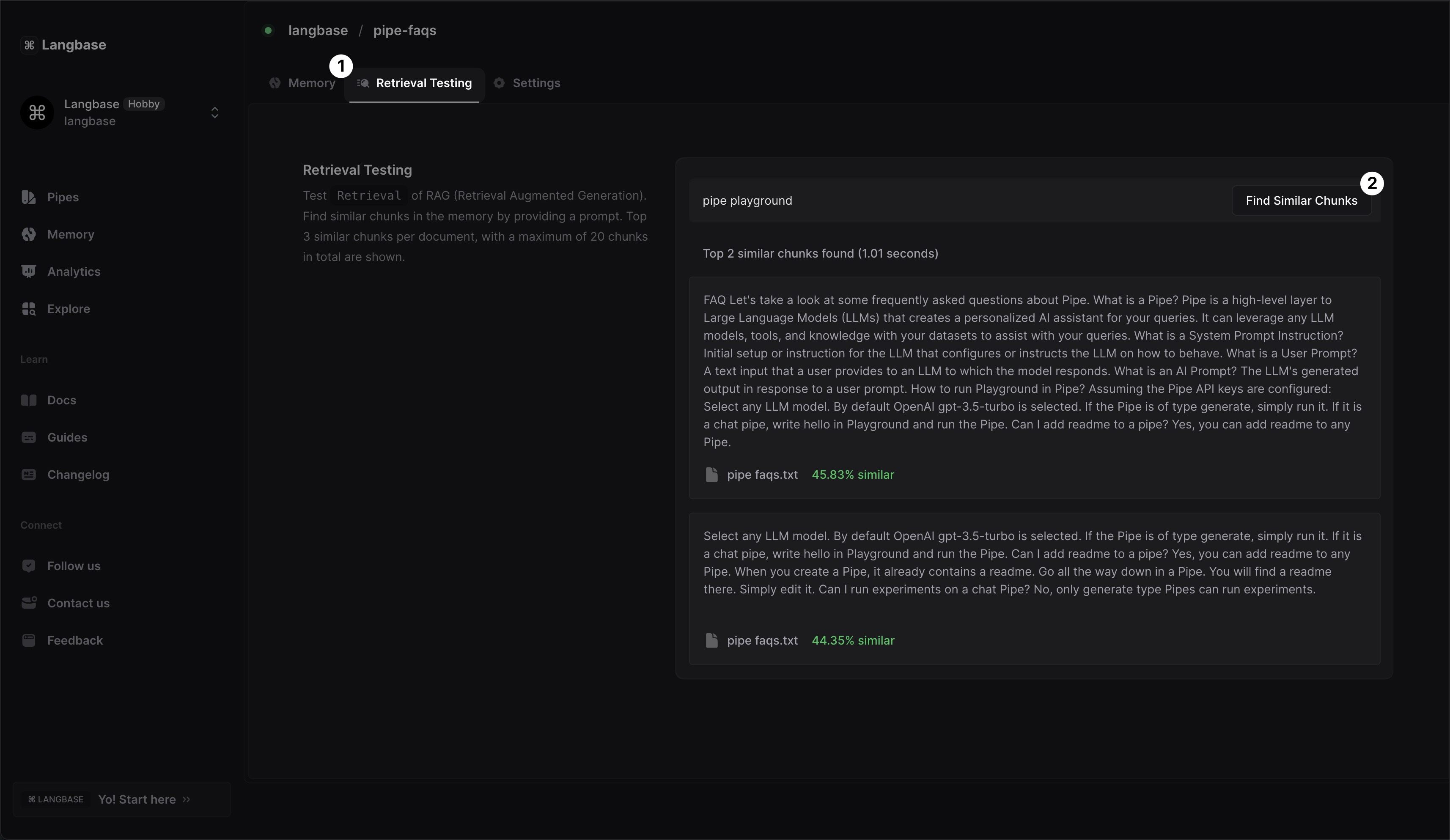
Retrieval testing is a way to test which parts of the document will be retrieved and passed on to LLM for a given prompt. It helps in debugging the document chunking parameters for your use case. If the retrieval testing is not showing the expected results, you can adjust the chunking parameters and re-run the retrieval test.
Below are the steps to run retrieval testing:
- In a memory, click on Retrieval Testing tab.
- Enter a prompt in the input box and click on the
Find Similar Chunksbutton.