Memory Agents
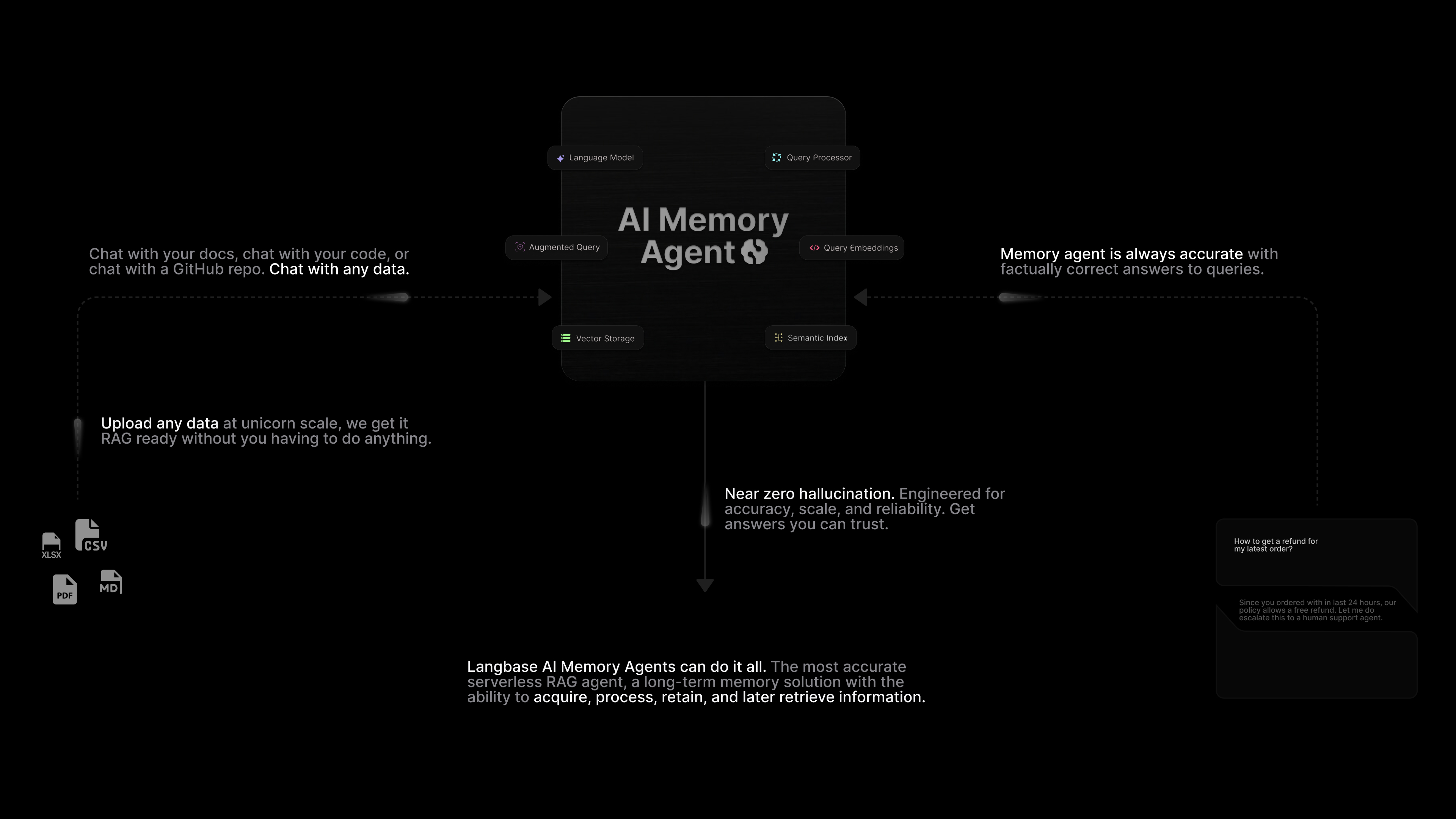
Memory agents are AI agents that have human like long-term memory. You can train AI agents with your data and knowledge base without having to manage vector storage, servers, or infrastructure.
Langbase memory agents represent the next frontier in semantic retrieval-augmented generation (RAG) as a serverless and infinitely scalable API designed for developers. 30-50x less expensive than the competition, with industry-leading accuracy in advanced agentic routing and intelligent reranking.
Large Language Models (LLMs) have a universal constraint. They don't know anything about your private data. They are trained on public data, and they hallucinate when you ask them questions they don't have the answers to.
Memory agents solve this problem by dynamically attaching private data to any LLM at scale, with industry-leading accuracy in advanced agentic routing and intelligent reranking.
Every Langbase org/user can have millions of personalized RAG knowledge bases tailored for individual users or specific use cases. Traditional vector storage architecture makes this impossible.
So, memory agents are a managed context search API for developers. Empowering developers with a long-term memory solution that can acquire, process, retain, and later retrieve information. Combining vector storage, RAG (Retrieval-Augmented Generation), and internet access to help you build powerful AI features and products.
Core functionality
- Upload: Upload documents, files, and web content to context
- Process: Automatically extract, embed, and create semantic index
- Query: Recall and retrieve relevant context using natural language queries
- Rerank: Automatically rerank retrieved results for higher relevance
- Accuracy: Near zero hallucinations with accurate context-aware information
Key features
- Semantic understanding: Go beyond keyword matching with context-aware search
- Vector storage: Efficient hybrid similarity search for large-scale data
- Semantic RAG: Enhance LLM outputs with retrieved information from Memory
- Internet access: Augment your private data with up-to-date web content
In a Retrieval Augmented Generation (RAG) system, Memory is used with Pipe agents to retrieve relevant data for queries.
The process involves:
- Creating query embeddings.
- Retrieving matching data from Memory.
- Augmenting the query with this data of 3-20 chunks.
- Using it to generate accurate, context-aware responses.
This integration ensures precise answers and enables use cases like document summarization, question-answering, and more.
Semantic Retrieval Augmented Generation (sRAG)
In a semantic RAG system, when an LLM is queried, it is provided with additional information relevant to the query from the Memory. This extra information helps the LLM to provide more accurate and relevant responses.
Below is the list of steps performed in a RAG system:
- Query: User queries the LLM through Pipe. Embeddings are generated for the query.
- Retrieval: Pipe retrieves query-relevant information from the Memory through similarity search.
- Augmentation: Retrieved information is augmented with the query.
- Generation: The augmented information is fed to the LLM to generate a response.
Next steps
Time to build. Check out the quickstart overview example or Explore the API reference.