
General Performance Metrics
| Category | Benchmark | o1-2024-12-17 | o1-preview |
|---|---|---|---|
| General | GPQA diamond | 75.7% | 73.3% |
| MMLU (pass @1) | 91.8% | 90.8% | |
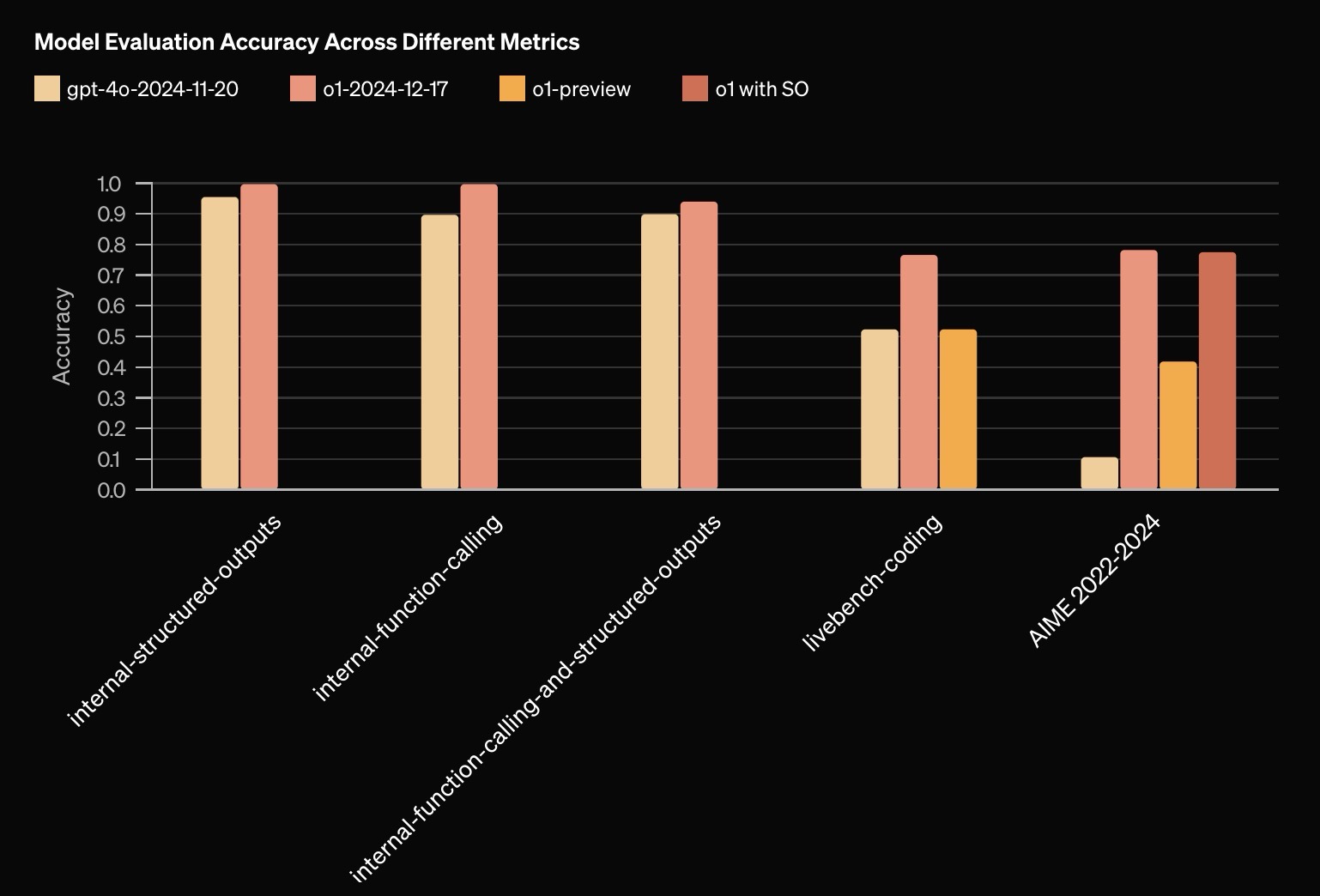
| Coding | SWE-bench Verified | 48.9% | 41.3% |
| LiveCodeBench | 76.6% | 52.3% | |
| Math | MATH (pass @1) | 96.4% | 85.5% |
| AIME 2024 (pass @1) | 79.2% | 42.0% | |
| MGSM (pass @1) | 89.3% | 90.8% | |
| Vision | MMMU (pass @1) | 77.3% | — |
| MathVista (pass @1) | 71.0% | — | |
| Factuality | SimpleQA | 42.6% | 42.4% |
| Agents | TAU-bench (retail) | 73.5% | — |
| TAU-bench (airline) | 54.2% | — |
Comparative PhD-Level Performance
| Subject | GPT-4o | o1 improvement |
|---|---|---|
| Chemistry | 40.2% | 64.7% |
| Physics | 59.5% | 92.8% |
| Biology | 61.6% | 69.2% |
Key Improvements Over Previous Models
-
Mathematics Performance
- 96.4% accuracy on MATH benchmark
- Significant improvement in AIME 2024 performance (79.2% vs 42.0%)
- Strong performance in general mathematical reasoning (MGSM: 89.3%)
-
Coding Capabilities
- 48.9% accuracy on SWE-bench Verified
- Notable improvement in LiveCodeBench (76.6% vs 52.3%)
-
Vision and Multimodal Tasks
- New capabilities in vision tasks with 77.3% accuracy on MMMU
- 71.0% accuracy on MathVista
These benchmarks demonstrate significant improvements across multiple domains, particularly in mathematics, coding, and multimodal tasks, while maintaining strong performance in general knowledge and reasoning capabilities.