Agent Architectures
At Langbase, we believe you don't need a framework. Build AI agents without any frameworks.
We’ll cover several different agent architectures that leverage Langbase to build, deploy, and scale autonomous agents. Define how your agents use LLMs, tools, memory, and durable workflows to process inputs, make decisions, and achieve goals.
Reference agent architectures
- Augmented LLM
- Prompt chaining
- Agentic Routing
- Agent Parallelization
- Orchestration workers
- Evaluator-optimizer
- Augmented LLM with Tools
- Memory Agent
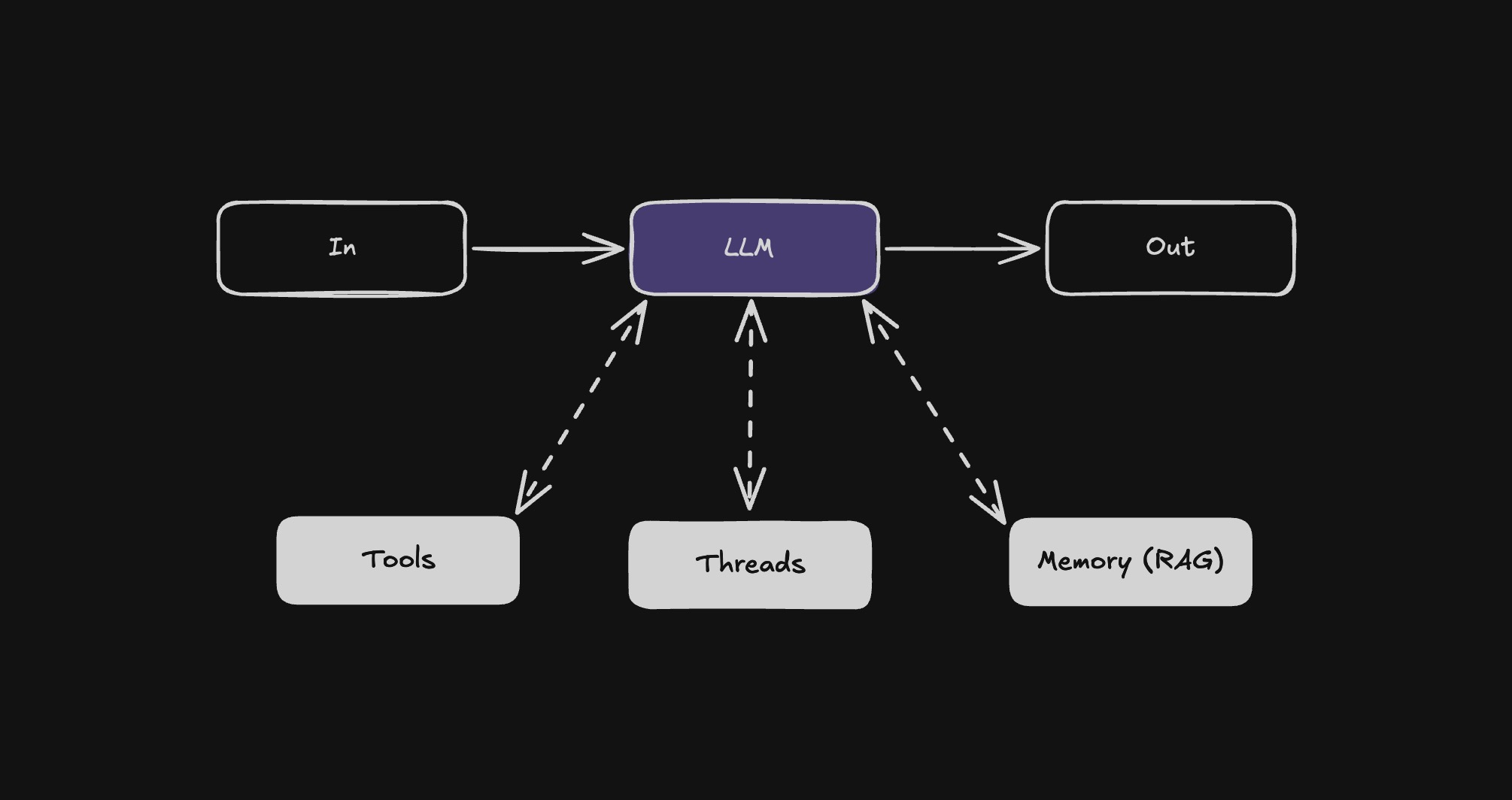
Langbase Augmented LLM (Pipe Agent) is the fundamental component of an agentic system. It is a Large Language Model (LLM) enhanced with augmentations such as retrieval, tools, and memory. Our current models can actively utilize these capabilities—generating their own search queries, selecting appropriate tools, and determining what information to retain using memory.
import dotenv from 'dotenv';
import { Langbase } from 'langbase';
dotenv.config();
const langbase = new Langbase({
apiKey: process.env.LANGBASE_API_KEY!,
});
async function main() {
// Create a pipe agent
const summaryAgent = await langbase.pipes.create({
name: "summary-agent",
model: "google:gemini-2.5-flash",
messages: [
{
role: "system",
content: 'You are a helpful assistant that summarizes text.'
}
]
});
// Run the pipe agent
const inputText = `Langbase is the most powerful serverless platform for building AI agents
with memory. Build, scale, and evaluate AI agents with semantic memory (RAG) and
world-class developer experience. We process billions of AI message tokens daily.
Built for every developer, not just AI/ML experts. Compared to complex AI frameworks,
Langbase is simple, serverless, and the first composable AI platform`;
const { completion } = await langbase.pipes.run({
name: summaryAgent.name,
stream: false,
messages: [
{
role: "user",
content: inputText,
}
],
});
console.log(completion);
}
main();
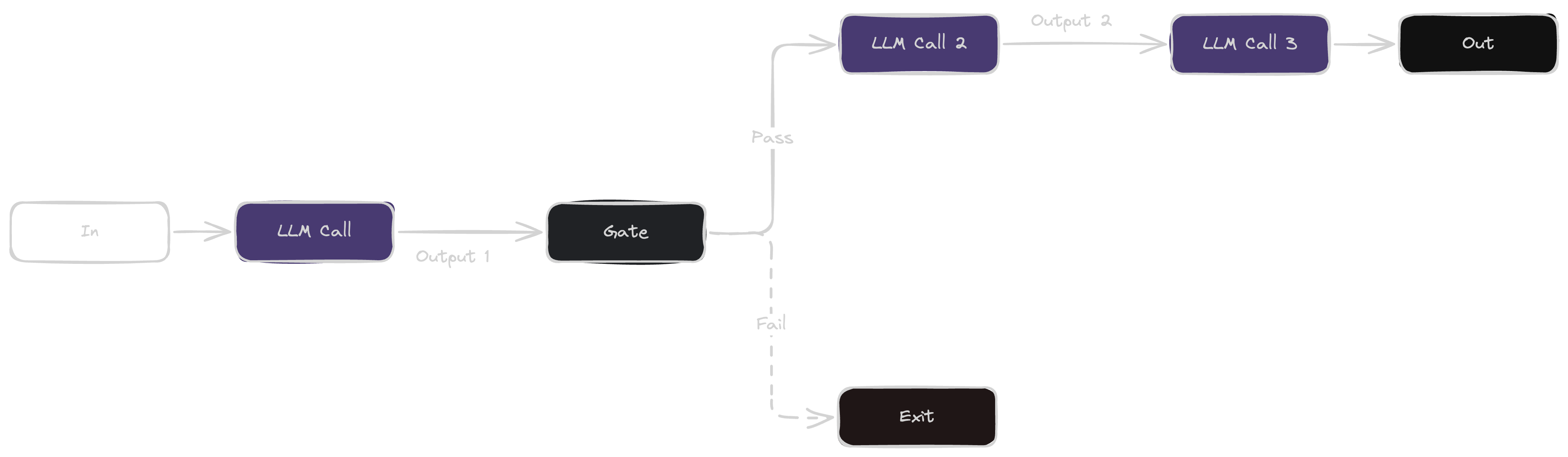
Prompt chaining splits a task into steps, with each LLM call using the previous step's result. It improves accuracy by simplifying each step, making it ideal for structured tasks like content generation and verification.
prompt-chaining.ts
import dotenv from 'dotenv';
import { Langbase } from 'langbase';
dotenv.config();
const langbase = new Langbase({
apiKey: process.env.LANGBASE_API_KEY!
});
async function main(inputText: string) {
// Prompt chaining steps
const steps = [
{
name: 'summary-agent',
model: 'google:gemini-2.5-flash',
description:
'summarize the product description into two concise sentences',
prompt: `Please summarize the following product description into two concise
sentences:\n`
},
{
name: 'features-agent',
model: 'google:gemini-2.5-flash',
description: 'extract key product features as bullet points',
prompt: `Based on the following summary, list the key product features as
bullet points:\n`
},
{
name: 'marketing-copy-agent',
model: 'google:gemini-2.5-flash',
description:
'generate a polished marketing copy using the bullet points',
prompt: `Using the following bullet points of product features, generate a
compelling and refined marketing copy for the product, be precise:\n`
}
];
// Create the pipe agents
await Promise.all(
steps.map(step =>
langbase.pipes.create({
name: step.name,
model: step.model,
messages: [
{
role: 'system',
content: `You are a helpful assistant that can ${step.description}.`
}
]
})
)
);
// Initialize the data with the raw input.
let data = inputText;
try {
// Process each step in the workflow sequentially.
for (const step of steps) {
// Call the LLM for the current step.
const response = await langbase.pipes.run({
stream: false,
name: step.name,
messages: [{ role: 'user', content: `${step.prompt} ${data}` }]
});
data = response.completion;
console.log(`Step: ${step.name} \n\n Response: ${data}`);
// Gate on summary agent output to ensure it is not too brief.
// If the summary is less than 10 words, throw an error to stop the workflow.
if (step.name === 'summary-agent' && data.split(' ').length < 10) {
throw new Error(
'Gate triggered for summary agent. The summary is too brief. Exiting workflow.'
);
return;
}
}
} catch (error) {
console.error('Error in main workflow:', error);
}
// The final refined marketing copy
console.log('Final Refined Product Marketing Copy:', data);
}
const inputText = `Our new smartwatch is a versatile device featuring a high-resolution display,
long-lasting battery life, fitness tracking, and smartphone connectivity. It's designed for
everyday use and is water-resistant. With cutting-edge sensors and a sleek design, it's
perfect for tech-savvy individuals.`;
main(inputText);
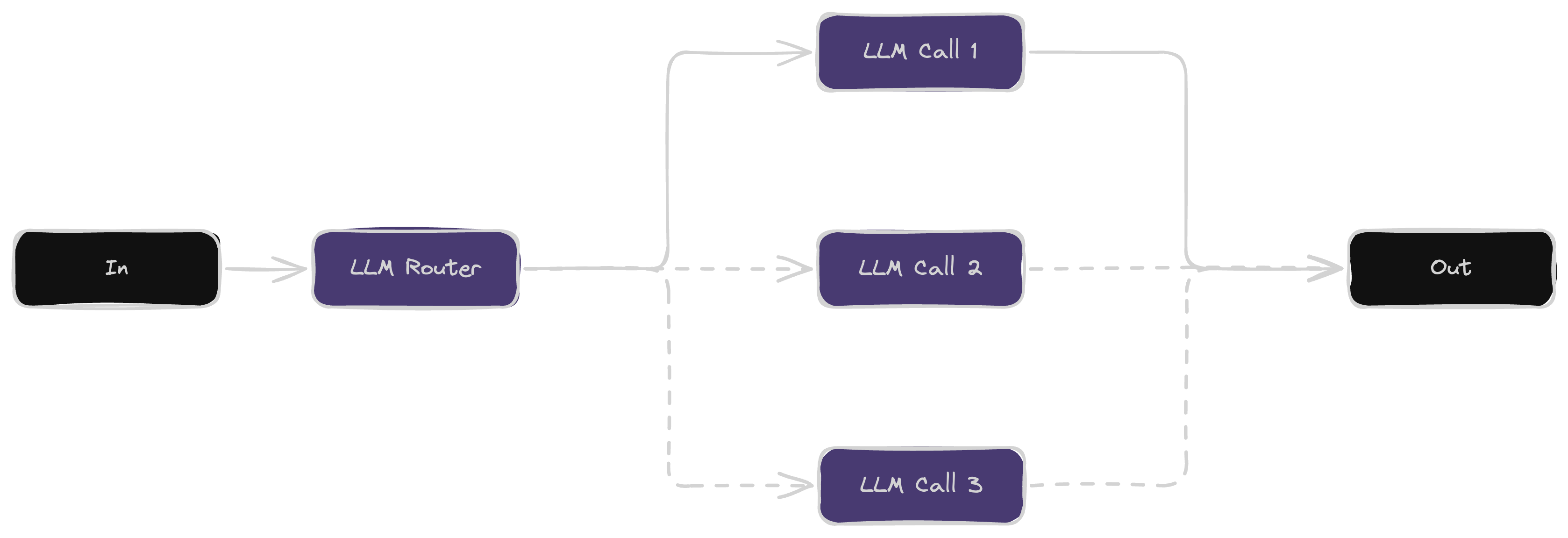
Routing classifies inputs and directs them to specialized LLMs for better accuracy. It helps optimize performance by handling different tasks separately, like sorting queries or assigning models based on complexity.
routing.ts
import dotenv from 'dotenv';
import { Langbase } from 'langbase';
dotenv.config();
// Initialize Langbase with your API key
const langbase = new Langbase({
apiKey: process.env.LANGBASE_API_KEY!
});
// Specialized agents configurations
const agentConfigs = {
router: {
name: 'router-agent',
model: 'google:gemini-2.5-flash',
prompt: `You are a router agent. Your job is to read the user's request and decide
which specialized agent is best suited to handle it.
Below are the agents you can route to:
- summary: Summarizes the text
- reasoning: Analyzes and provides reasoning for the text
- coding: Provides a coding solution for the text
Only respond with valid JSON that includes a single field "agent" whose value must
be one of ["summary", "reasoning", "coding"] based on the user's request.
For example: {"agent":"summary"}.
No additional text or explanation—just the JSON.
`
},
summary: {
name: 'summary-agent',
model: 'google:gemini-2.5-flash',
prompt: 'Summarize the following text:\n'
},
reasoning: {
name: 'reasoning-agent',
model: 'groq:deepseek-r1-distill-llama-70b',
prompt: 'Analyze and provide reasoning for:\n'
},
coding: {
name: 'coding-agent',
model: 'anthropic:claude-3-5-sonnet-latest',
prompt: 'Provide a coding solution for:\n'
}
};
// Create the router and specialized agent pipes
async function createPipes() {
// Create router and all specialized agent
await Promise.all(
Object.entries(agentConfigs).map(([key, config]) =>
langbase.pipes.create({
name: config.name,
model: config.model,
messages: [
{
role: 'system',
content: config.prompt
}
]
})
)
);
}
// Router agent
async function routerAgent(inputText: string) {
const response = await langbase.pipes.run({
stream: false,
name: 'router-agent',
messages: [
{
role: 'user',
content: inputText
}
]
});
// The router's response should look like: {"agent":"summary"} or {"agent":"reasoning"} or {"agent":"coding"}
// We parse the completion to extract the agent value
return JSON.parse(response.completion);
}
async function main(inputText: string) {
try {
// Create pipes first
await createPipes();
// Step A: Determine which agent to route to
const route = await routerAgent(inputText);
console.log('Router decision:', route);
// Step B: Call the appropriate agent
const agent = agentConfigs[route.agent];
const response = await langbase.pipes.run({
stream: false,
name: agent.name,
messages: [
{ role: 'user', content: `${agent.prompt} ${inputText}` }
]
});
// Final output
console.log(
`Agent: ${agent.name} \n\n Response: ${response.completion}`
);
} catch (error) {
console.error('Error in main workflow:', error);
}
}
// Example usage:
const inputText = 'Why days are shorter in winter?';
main(inputText);
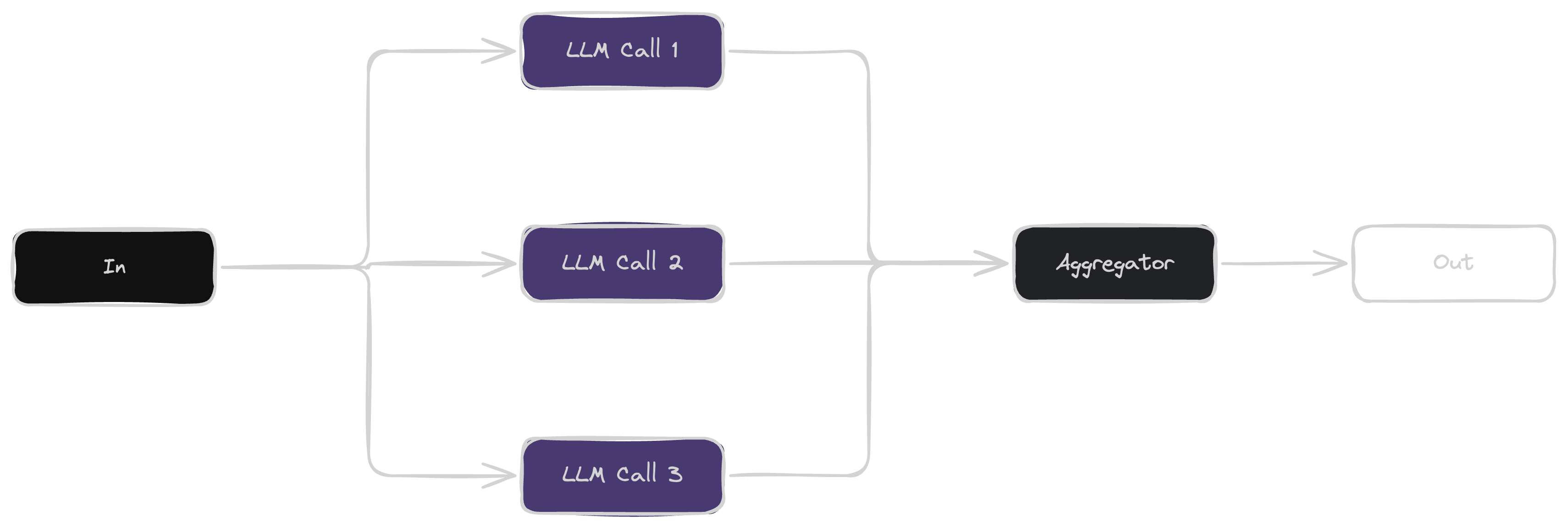
Parallelization runs multiple LLM tasks at the same time to improve speed or accuracy. It works by splitting a task into independent parts (sectioning) or generating multiple responses for comparison (voting).
Voting is a parallelization method where multiple LLM calls generate different responses for the same task. The best result is selected based on agreement, predefined rules, or quality evaluation, improving accuracy and reliability.
parallelization.ts
import { Langbase } from 'langbase';
import dotenv from 'dotenv';
dotenv.config();
const langbase = new Langbase({
apiKey: process.env.LANGBASE_API_KEY!
});
// Agent configurations
const agentConfigs = {
sentiment: {
name: 'email-sentiment',
model: 'openai:gpt-4.1-mini',
prompt: `
You are a helpful assistant that can analyze the sentiment of the email.
Only respond with the sentiment, either "positive", "negative" or "neutral".
Do not include any markdown formatting, code blocks, or backticks in your response.
The response should be a raw JSON object that can be directly parsed.
Example response:
{
"sentiment": "positive"
}
`
},
summary: {
name: 'email-summary',
model: 'openai:gpt-4.1-mini',
prompt: `
You are a helpful assistant that can summarize the email.
Only respond with the summary.
Do not include any markdown formatting, code blocks, or backticks in your response.
The response should be a raw JSON object that can be directly parsed.
Example response:
{
"summary": "The email is about a product that is not working."
}
`
},
decisionMaker: {
name: 'email-decision-maker',
model: 'openai:gpt-4.1-mini',
prompt: `
You are a decision maker that analyzes and decides if the given email requires
a response or not.
Make sure to check if the email is spam or not. If the email is spam, then it
does not need a response.
If it requires a response, based on the email urgency, decide on the response
date. Also, define the response priority.
Use the following keys and values accordingly
- respond: true or false
- category: spam or not spam
- priority: low, medium, high, urgent
Do not include any markdown formatting, code blocks, or backticks in your response.
The response should be a raw JSON object that can be directly parsed.
`
}
};
// Create all pipes
async function createPipes() {
await Promise.all(
Object.entries(agentConfigs).map(([key, config]) =>
langbase.pipes.create({
name: config.name,
model: config.model,
json: true,
messages: [
{
role: 'system',
content: config.prompt
}
]
})
)
);
}
async function main(emailInput: string) {
try {
// Create pipes first
await createPipes();
// Sentiment analysis
const emailSentimentAgent = async (email: string) => {
const response = await langbase.pipes.run({
name: agentConfigs.sentiment.name,
stream: false,
messages: [
{
role: 'user',
content: email
}
]
});
return JSON.parse(response.completion).sentiment;
};
// Summarize email
const emailSummaryAgent = async (email: string) => {
const response = await langbase.pipes.run({
name: agentConfigs.summary.name,
stream: false,
messages: [
{
role: 'user',
content: email
}
]
});
return JSON.parse(response.completion).summary;
};
// Determine if a response is needed
const emailDecisionMakerAgent = async (
summary: string,
sentiment: string
) => {
const response = await langbase.pipes.run({
name: agentConfigs.decisionMaker.name,
stream: false,
messages: [
{
role: 'user',
content: `Email summary: ${summary}\nEmail sentiment: ${sentiment}`
}
]
});
return JSON.parse(response.completion);
};
// Parallelize the requests
const [emailSentiment, emailSummary] = await Promise.all([
emailSentimentAgent(emailInput),
emailSummaryAgent(emailInput)
]);
console.log('Email Sentiment:', emailSentiment);
console.log('Email Summary:', emailSummary);
// aggregator based on the results
const emailDecision = await emailDecisionMakerAgent(
emailSummary,
emailSentiment
);
console.log('should respond:', emailDecision.respond);
console.log('category:', emailDecision.category);
console.log('priority:', emailDecision.priority);
return emailDecision;
} catch (error) {
console.error('Error in main workflow:', error);
}
}
const email = `
Hi John,
I'm really disappointed with the service I received yesterday. The product
was faulty, and customer support was unhelpful. How can I apply for a refund?
Thanks,
`;
main(email);
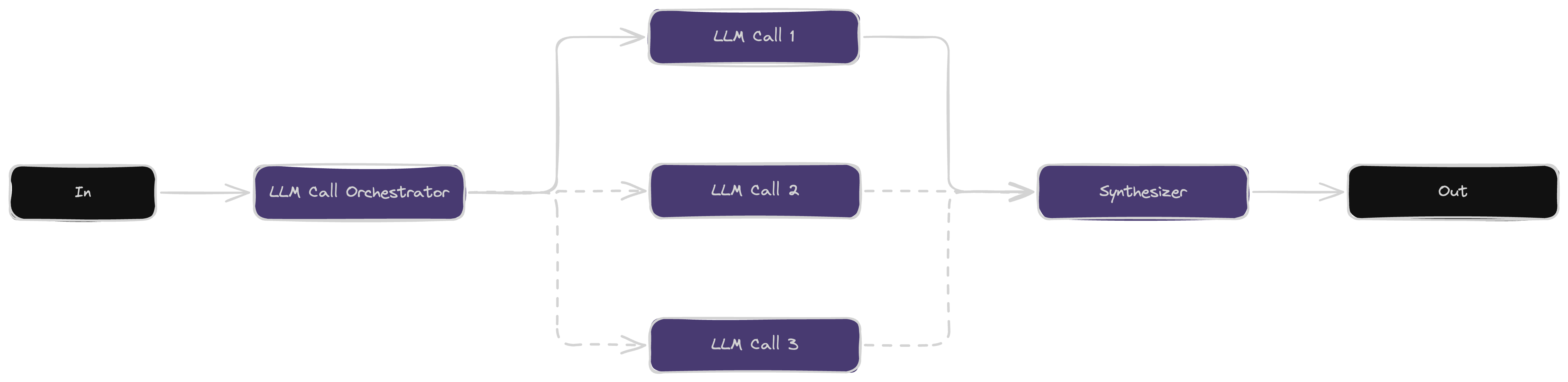
The orchestrator-workers workflow has a main LLM (orchestrator) that breaks a task into smaller parts and assigns them to worker LLMs. The orchestrator then gathers their results to complete the task, making it useful for complex and unpredictable jobs.
orchestration-worker.ts
import dotenv from 'dotenv';
import { Langbase } from 'langbase';
dotenv.config();
const langbase = new Langbase({
apiKey: process.env.LANGBASE_API_KEY!
});
// Agent configurations
const agentConfigs = {
orchestrator: {
name: 'orchestrator',
model: 'google:gemini-2.5-flash',
prompt: `
You are an orchestrator agent. Analyze the user's task and break it into
smaller and distinct subtasks. Return your response in JSON format with:
- An analysis of the task extracted from the task. No extra steps like
proofreading, summarizing, etc.
- A list of subtasks, each with a "description" (what needs to be done).
Do not include any markdown formatting, code blocks, or backticks in your response.
The response should be a raw JSON object that can be directly parsed.
Example response:
{
"analysis": "The task is to describe the benefits and drawbacks of electric cars",
"subtasks": [
{ "description": "Write about the benefits of electric cars." },
{ "description": "Write about the drawbacks of electric cars." }
]
}
`
},
worker: {
name: 'worker-agent',
model: 'google:gemini-2.5-flash',
prompt: `
You are a worker agent working on a specific part of a larger task.
You are given a subtask and you need to complete it.
You are given the original task and the subtask.
You need to complete the subtask.
`
},
synthesizer: {
name: 'synthesizer-agent',
model: 'google:gemini-2.5-flash',
prompt: `You are an expert synthesizer agent. Combine the following results into a
cohesive final output.`
}
};
// Create all pipes
async function createPipes() {
await Promise.all(
Object.entries(agentConfigs).map(([key, config]) =>
langbase.pipes.create({
name: config.name,
model: config.model,
messages: [
{
role: 'system',
content: config.prompt
}
]
})
)
);
}
// Main orchestration workflow
async function orchestratorAgent(task: string) {
try {
// Create pipes first
await createPipes();
// Step 1: Use the orchestrator LLM to break down the task
const orchestrationResults = await langbase.pipes.run({
stream: false,
name: agentConfigs.orchestrator.name,
messages: [
{
role: 'user',
content: `Task: ${task}`
}
]
});
// Parse the orchestrator's JSON response
const { analysis, subtasks } = JSON.parse(
orchestrationResults.completion
);
console.log('Task Analysis:', analysis);
console.log('Generated Subtasks:', subtasks);
// Step 2: Process each subtask in parallel using worker LLMs
const workerAgentsResults = await Promise.all(
subtasks.map(async subtask => {
const workerAgentResult = await langbase.pipes.run({
stream: false,
name: agentConfigs.worker.name,
messages: [
{
role: 'user',
content: `
The original task is:
"${task}"
Your specific subtask is:
"${subtask.description}"
Provide a concise response for this subtask. Only respond with the
response for the subtask.
`
}
]
});
return { subtask, result: workerAgentResult.completion };
})
);
// Step 3: Synthesize all results into a final output
const synthesizerAgentInput = workerAgentsResults
.map(
workerResponse =>
`Subtask Description: ${workerResponse.subtask.description}\n
Result:\n${workerResponse.result}`
)
.join('\n\n');
const synthesizerAgentResult = await langbase.pipes.run({
stream: false,
name: agentConfigs.synthesizer.name,
messages: [
{
role: 'user',
content: `Combine the following results into a complete solution:\n
${synthesizerAgentInput}`
}
]
});
console.log(
'Final Synthesized Output:\n',
synthesizerAgentResult.completion
);
return synthesizerAgentResult.completion;
} catch (error) {
console.error('Error in orchestration workflow:', error);
throw error;
}
}
// Example usage
async function main() {
const task = `
Write a blog post about the benefits of remote work.
Include sections on productivity, work-life balance, and environmental impact.
`;
await orchestratorAgent(task);
}
main();

The evaluator-optimizer workflow uses one LLM to generate a response and another to review and improve it. This cycle repeats until the result meets the desired quality, making it useful for tasks that benefit from iterative refinement.
evaluator-optimizer.ts
import dotenv from 'dotenv';
import { Langbase } from 'langbase';
dotenv.config();
const langbase = new Langbase({
apiKey: process.env.LANGBASE_API_KEY!
});
// Agent configurations
const agentConfigs = {
generator: {
name: 'generator-agent',
model: 'google:gemini-2.5-flash',
prompt: `
You are a skilled assistant tasked with creating or improving a product description.
Your goal is to produce a concise, engaging, and informative description based on
the task and feedback provided.
`
},
evaluator: {
name: 'evaluator-agent',
model: 'google:gemini-2.5-flash',
prompt: `
You are an evaluator agent tasked with reviewing a product description.
If the description matches the requirements and needs no further changes, respond just with "ACCEPTED" and nothing else.
ONLY suggest changes if it is not ACCEPTED.
If not accepted, provide constructive feedback on how to improve it based on the original task requirements.
`
}
};
// Create all pipes
async function createPipes() {
await Promise.all(
Object.entries(agentConfigs).map(([key, config]) =>
langbase.pipes.create({
name: config.name,
model: config.model,
messages: [
{
role: 'system',
content: config.prompt
}
]
})
)
);
}
// Main evaluator-optimizer workflow
async function evaluatorOptimizerWorkflow(task: string) {
try {
// Create pipes first
await createPipes();
let solution = ''; // The solution being refined
let feedback = ''; // Feedback from the evaluator
let iteration = 0;
const maxIterations = 5; // Limit to prevent infinite loops
while (iteration < maxIterations) {
console.log(`\n--- Iteration ${iteration + 1} ---`);
// Step 1: Generator creates or refines the solution
const generatorResponse = await langbase.pipes.run({
stream: false,
name: agentConfigs.generator.name,
messages: [
{
role: 'user',
content: `
Task: ${task}
Previous Feedback (if any): ${feedback}
Create or refine the product description accordingly.
`
}
]
});
solution = generatorResponse.completion;
console.log('Generated Solution:', solution);
// Step 2: Evaluator provides feedback
const evaluatorResponse = await langbase.pipes.run({
stream: false,
name: agentConfigs.evaluator.name,
messages: [
{
role: 'user',
content: `
Original requirements:
"${task}"
Current description:
"${solution}"
Please evaluate it and provide feedback or indicate if it is acceptable.
`
}
]
});
feedback = evaluatorResponse.completion.trim();
console.log('Evaluator Feedback:', feedback);
// Step 3: Check if the solution is accepted
if (feedback.toUpperCase() === 'ACCEPTED') {
console.log('\nFinal Solution Accepted:', solution);
return solution;
}
iteration++;
}
console.log('\nMax iterations reached. Final Solution:', solution);
return solution;
} catch (error) {
console.error('Error in evaluator-optimizer workflow:', error);
throw error;
}
}
// Example usage
async function main() {
const task = `
Write a product description for an eco-friendly water bottle.
The target audience is environmentally conscious millennials.
Key features include: plastic-free materials, insulated design,
and a lifetime warranty.
`;
await evaluatorOptimizerWorkflow(task);
}
main();
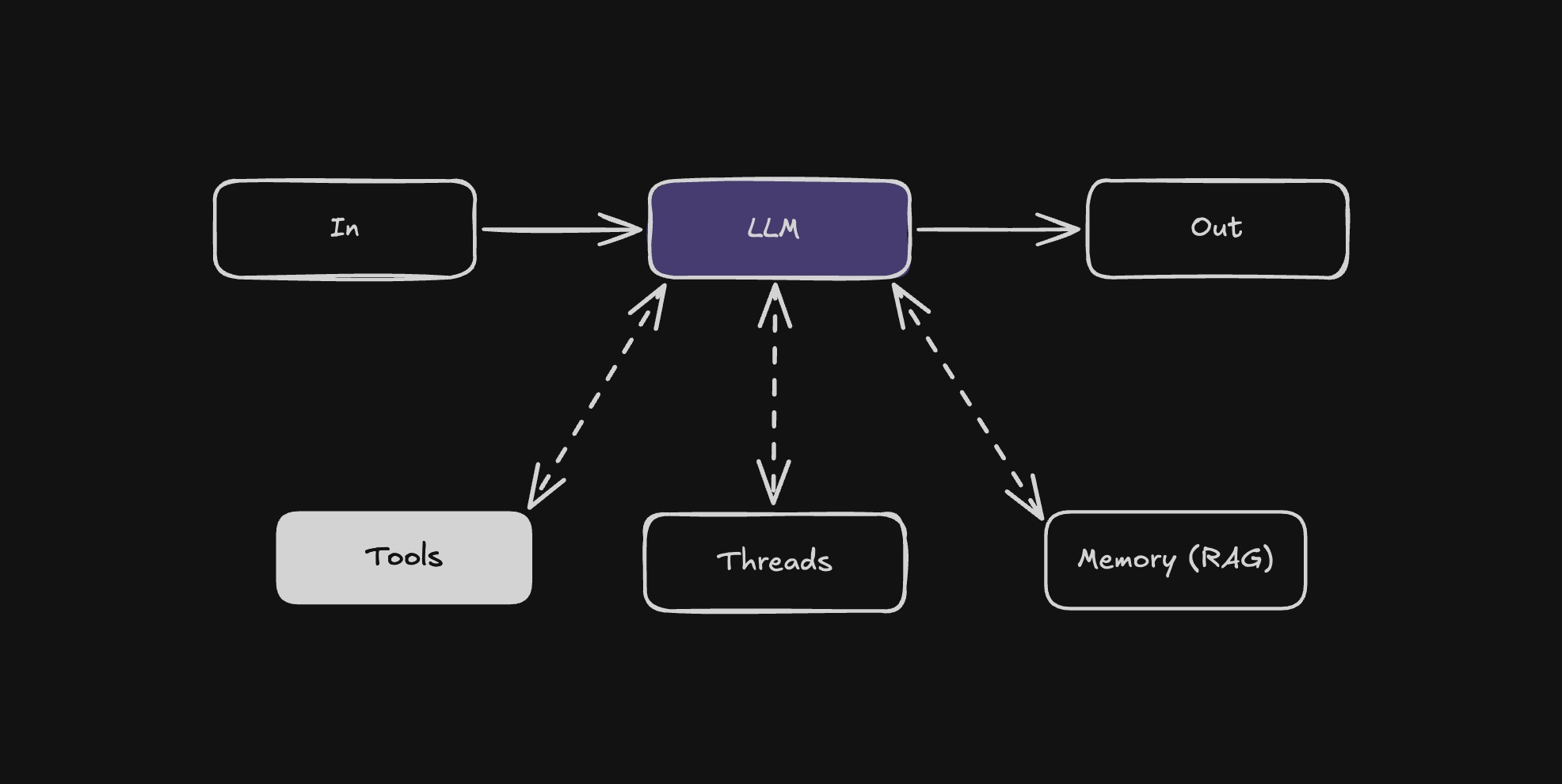
Langbase pipe agent is the fundamental component of an agentic system. It is a Large Language Model (LLM) enhanced with augmentations such as retrieval, tools, and memory. Our current models can actively utilize these capabilities—generating their own search queries, selecting appropriate tools, and determining what information to retain using memory.
import dotenv from 'dotenv';
import { Langbase, getToolsFromRun, Message, Tools } from "langbase";
dotenv.config();
const langbase = new Langbase({
apiKey: process.env.LANGBASE_API_KEY!,
});
async function main() {
// Create a pipe agent
const weatherPipeAgent = await langbase.pipes.create({
name: "langbase-weather-pipe-agent",
model: "google:gemini-2.5-flash",
messages: [
{
role: "system",
content: 'You are a helpful assistant that can get the weather of a given location.',
}
]
});
// Define a weather tool
const weatherTool = {
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather of a given location",
"parameters": {
"type": "object",
"required": [
"location"
],
"properties": {
"unit": {
"enum": [
"celsius",
"fahrenheit"
],
"type": "string"
},
"location": {
"type": "string",
"description": "The city and state, e.g., San Francisco, CA"
}
}
}
}
}
function get_current_weather() {
return "It's 70 degrees and sunny in SF.";
}
const tools = {
get_current_weather,
};
// Run the pipe agent with the tool
const response = await langbase.pipes.run({
name: weatherPipeAgent.name,
messages: [
{
role: "user",
content: 'What is the weather in San Francisco?',
}
],
tools: [weatherTool],
stream: false,
});
const toolsFromRun = await getToolsFromRun(response);
const hasToolCalls = toolsFromRun.length > 0;
if (hasToolCalls) {
const messages: Message[] = [];
// call all the functions in the toolCalls array
toolsFromRun.forEach(async toolCall => {
const toolName = toolCall.function.name;
const toolParameters = JSON.parse(toolCall.function.arguments);
const toolFunction = tools[toolName];
const toolResult = toolFunction(toolParameters); // Call the tool function with the tool parameters
messages.push({
tool_call_id: toolCall.id,
role: 'tool',
name: toolName,
content: toolResult,
});
});
const { completion } = await langbase.pipes.run({
messages,
name: weatherPipeAgent.name,
threadId: response.threadId,
stream: false,
});
console.log(completion);
} else {
// No tool calls, just return the completion
console.log(response.completion);
}
}
main();
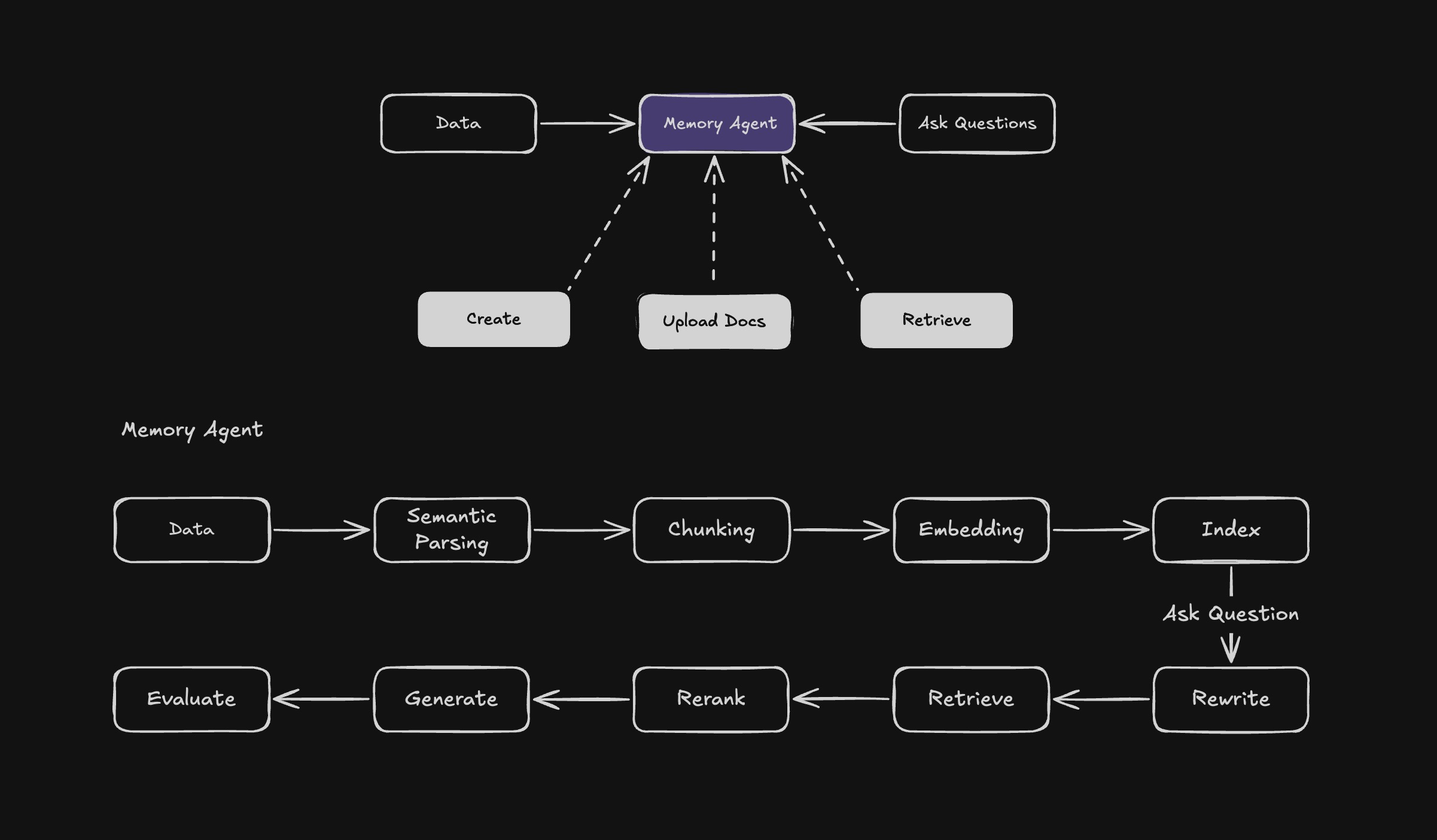
Langbase memory agents represent the next frontier in semantic retrieval-augmented generation (RAG) as a serverless and infinitely scalable API designed for developers. 30-50x less expensive than the competition, with industry-leading accuracy in advanced agentic routing, retrieval, and more.
Memory Agent Example
import { Langbase } from "langbase";
import dotenv from "dotenv";
import downloadFile from "./download-file";
dotenv.config();
const langbase = new Langbase({
apiKey: process.env.LANGBASE_API_KEY!,
});
async function main() {
// Step 1: Create a memory
const memory = await langbase.memories.create({
name: "employee-handbook-memory",
description: "Memory for employee handbook",
});
console.log("Memory created:", memory.name);
// Step 2: Download the employee handbook file
const fileUrl =
"https://raw.githubusercontent.com/LangbaseInc/langbase-examples/main/assets/employee-handbook.txt";
const fileName = "employee-handbook.txt";
const fileContent = await downloadFile(fileUrl);
// Step 3: Upload the employee handbook to memory
await langbase.memories.documents.upload({
memoryName: memory.name,
contentType: "text/plain",
documentName: fileName,
document: fileContent,
});
console.log("Employee handbook uploaded to memory");
// Step 4: Create a pipe
const pipe = await langbase.pipes.create({
name: "employee-handbook-pipe",
model: "google:gemini-2.5-flash",
description: "Pipe for querying employee handbook",
memory: [{ name: "employee-handbook-memory" }],
});
console.log("Pipe created:", pipe.name);
// Step 5: Ask a question
const question = "What is the company policy on remote work?";
const { completion } = await langbase.pipes.run({
name: "employee-handbook-pipe",
messages: [{ role: "user", content: question }],
stream: false,
});
console.log("Question:", question);
console.log("Answer:", completion);
}
main().catch(console.error);