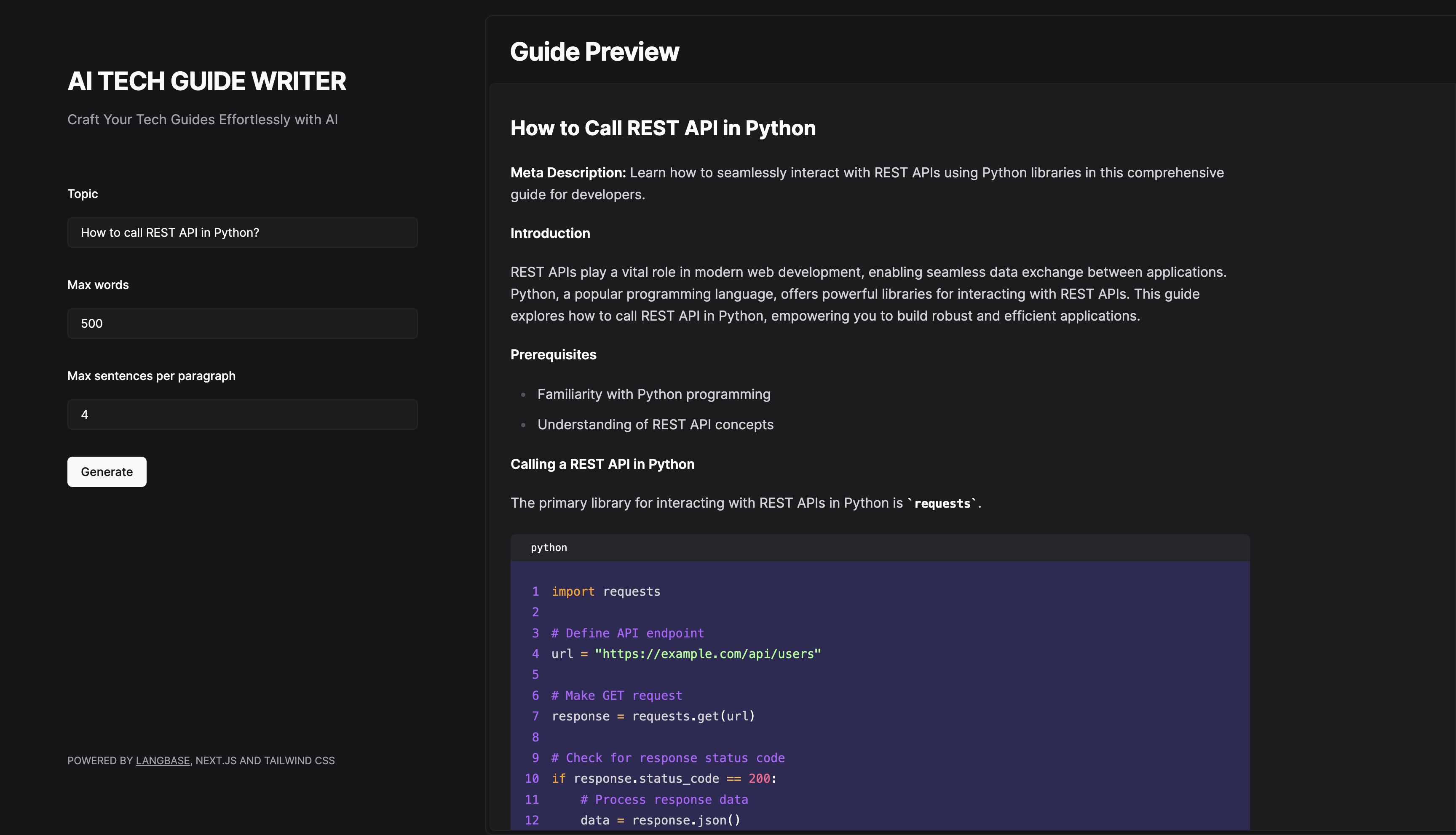
Generate Text Completions
Enter a topic and click the button to generate titles using LLM
setTopic(e.target.value)} /> {loading &&Loading...
} {completion && (Generated Titles:
-
{completion}
 ---
## AI Chatbot
This example uses a [chatbot](https://langbase.com/examples/ai-chatbot) Pipe on Langbase to create an efficient, streaming-enabled chatbot for any use-case. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://ai-chatbot.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/ai-chatbot) to see how easy it is to build an app using Pipe.
---
## AI Chatbot
This example uses a [chatbot](https://langbase.com/examples/ai-chatbot) Pipe on Langbase to create an efficient, streaming-enabled chatbot for any use-case. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://ai-chatbot.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/ai-chatbot) to see how easy it is to build an app using Pipe.
 ---
## ASCII Software Architect
This example uses a [chatbot](https://langbase.com/examples/ascii-software-architect) Pipe on Langbase to create ASCII Software Architect, which generates ASCII UML Class diagrams for code comprehension, design documentation, collaborative planning, and legacy system analysis. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://ascii-software-architect.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/ascii-software-architect) to see how easy it is to build an app using Pipe and Chat UI. To use this chatbot, you can select one of the suggestions presented in the menu. See conversation tips to get the best results out of this chatbot.
---
## ASCII Software Architect
This example uses a [chatbot](https://langbase.com/examples/ascii-software-architect) Pipe on Langbase to create ASCII Software Architect, which generates ASCII UML Class diagrams for code comprehension, design documentation, collaborative planning, and legacy system analysis. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://ascii-software-architect.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/ascii-software-architect) to see how easy it is to build an app using Pipe and Chat UI. To use this chatbot, you can select one of the suggestions presented in the menu. See conversation tips to get the best results out of this chatbot.
 ---
## Expert Proofreader
This example uses a [chatbot](https://langbase.com/examples/expert-proofreader) Pipe on Langbase to create Expert Proofreader, refining language, ensuring style consistency, correcting grammar, and enhancing clarity while preserving accuracy. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://expert-proofreader.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/expert-proofreader) to see how easy it is to build an app using Pipe and Chat UI. To use the Expert Proofreader chatbot, you can select one of the suggestions presented in the menu. See conversation tips to get the best results.
---
## Expert Proofreader
This example uses a [chatbot](https://langbase.com/examples/expert-proofreader) Pipe on Langbase to create Expert Proofreader, refining language, ensuring style consistency, correcting grammar, and enhancing clarity while preserving accuracy. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://expert-proofreader.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/expert-proofreader) to see how easy it is to build an app using Pipe and Chat UI. To use the Expert Proofreader chatbot, you can select one of the suggestions presented in the menu. See conversation tips to get the best results.
 ---
## JavaScript Tutor
This example uses a [chatbot](https://langbase.com/examples/js-tutor) Pipe on Langbase to create JavaScript Tutor, offering interactive lessons, progress tracking, quizzes, and the ability to skip levels for targeted learning. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://js-tutor.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/js-tutor) to see how easy it is to build an app using Pipe. To use this chatbot, select the suggestion presented in the menu. See conversation tips for the best results.
---
## JavaScript Tutor
This example uses a [chatbot](https://langbase.com/examples/js-tutor) Pipe on Langbase to create JavaScript Tutor, offering interactive lessons, progress tracking, quizzes, and the ability to skip levels for targeted learning. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://js-tutor.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/js-tutor) to see how easy it is to build an app using Pipe. To use this chatbot, select the suggestion presented in the menu. See conversation tips for the best results.
 ---
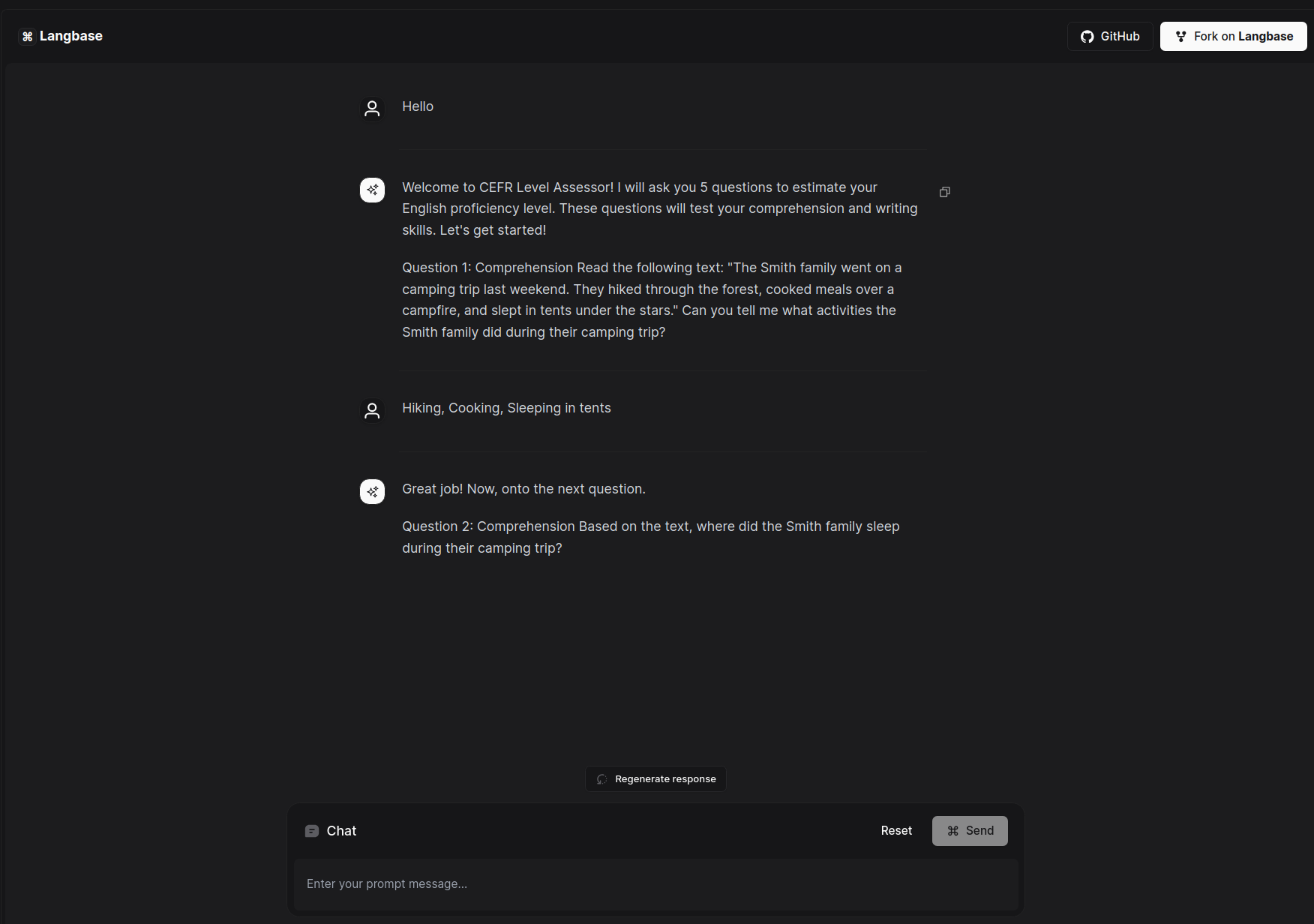
## English CEFR Level Assessment Bot
This example uses a [chatbot](https://langbase.com/examples/cefr-level-assessment-bot) Pipe on Langbase to create English CEFR Level Assessment Bot, an AI Assistant that assess your english language skills based on interactive skill assessment test (comprehension and writing). It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://cefr-level-assessment-bot.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/cefr-level-assessment-bot) to see how easy it is to build an app using Pipe and Chat UI. To use English CEFR Level Assessment Bot,
interact with the chatbot by answering questions. At the end of the interactive conversation/test, you can receive a rough assessment of your english proficiency from the English CEFR Level Assessment chatbot.
---
## English CEFR Level Assessment Bot
This example uses a [chatbot](https://langbase.com/examples/cefr-level-assessment-bot) Pipe on Langbase to create English CEFR Level Assessment Bot, an AI Assistant that assess your english language skills based on interactive skill assessment test (comprehension and writing). It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://cefr-level-assessment-bot.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/cefr-level-assessment-bot) to see how easy it is to build an app using Pipe and Chat UI. To use English CEFR Level Assessment Bot,
interact with the chatbot by answering questions. At the end of the interactive conversation/test, you can receive a rough assessment of your english proficiency from the English CEFR Level Assessment chatbot.
 ---
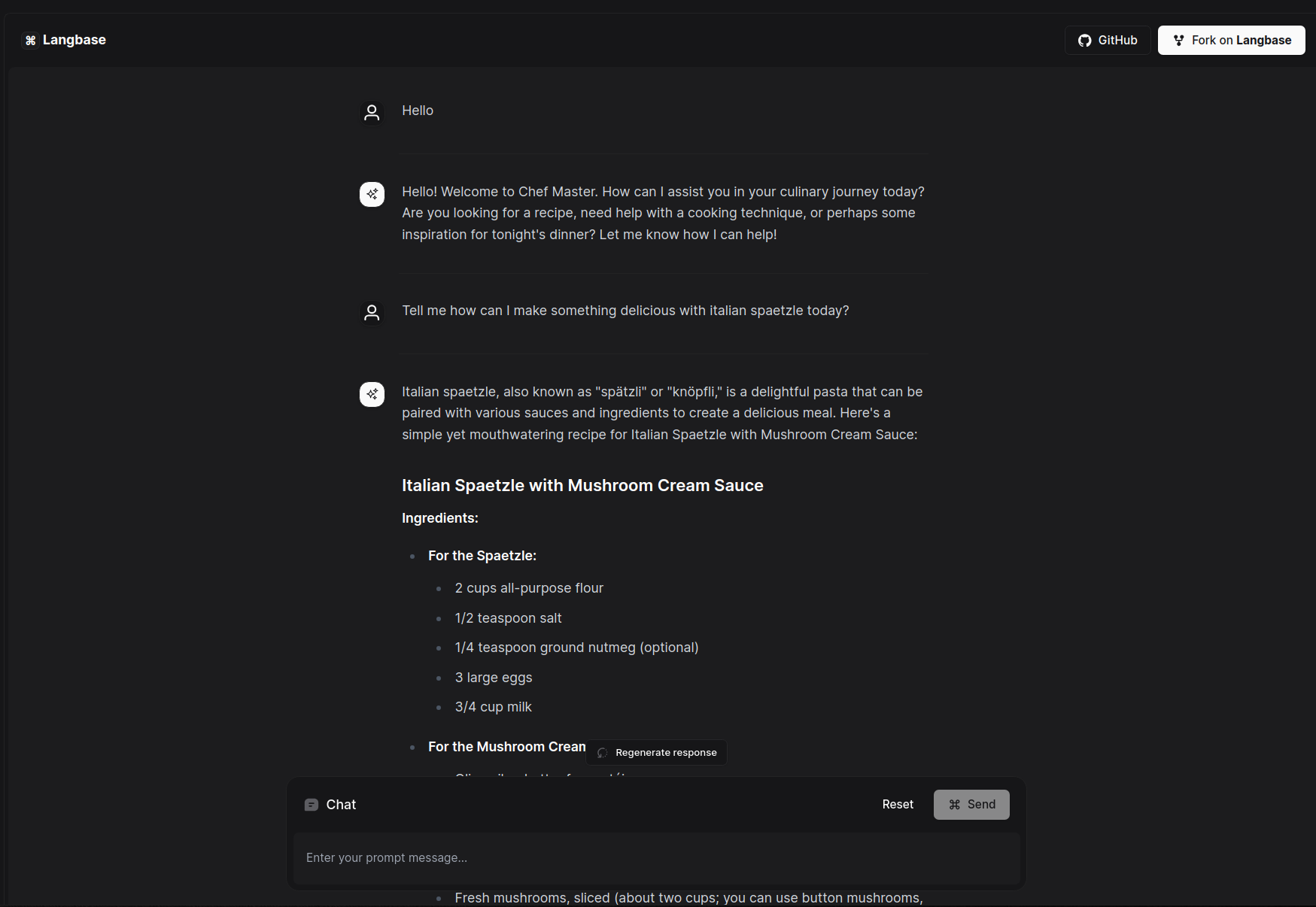
## AI Master Chef
This example uses a [chatbot](https://langbase.com/examples/ai-master-chef) Pipe on Langbase to create AI MasterChef, your ultimate culinary assistant, designed to inspire home cooks, aspiring chefs, and food enthusiasts alike. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://ai-master-chef.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/ai-master-chef) to see how easy it is to build an app using Pipe and Chat UI. To use AI Master Chef
you can use the following text as an example:
```
You: Hello
AI Master Chef: ...
You: I have rice and chicken help me cook something delicious today
```
---
## AI Master Chef
This example uses a [chatbot](https://langbase.com/examples/ai-master-chef) Pipe on Langbase to create AI MasterChef, your ultimate culinary assistant, designed to inspire home cooks, aspiring chefs, and food enthusiasts alike. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://ai-master-chef.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/ai-master-chef) to see how easy it is to build an app using Pipe and Chat UI. To use AI Master Chef
you can use the following text as an example:
```
You: Hello
AI Master Chef: ...
You: I have rice and chicken help me cook something delicious today
```
 ---
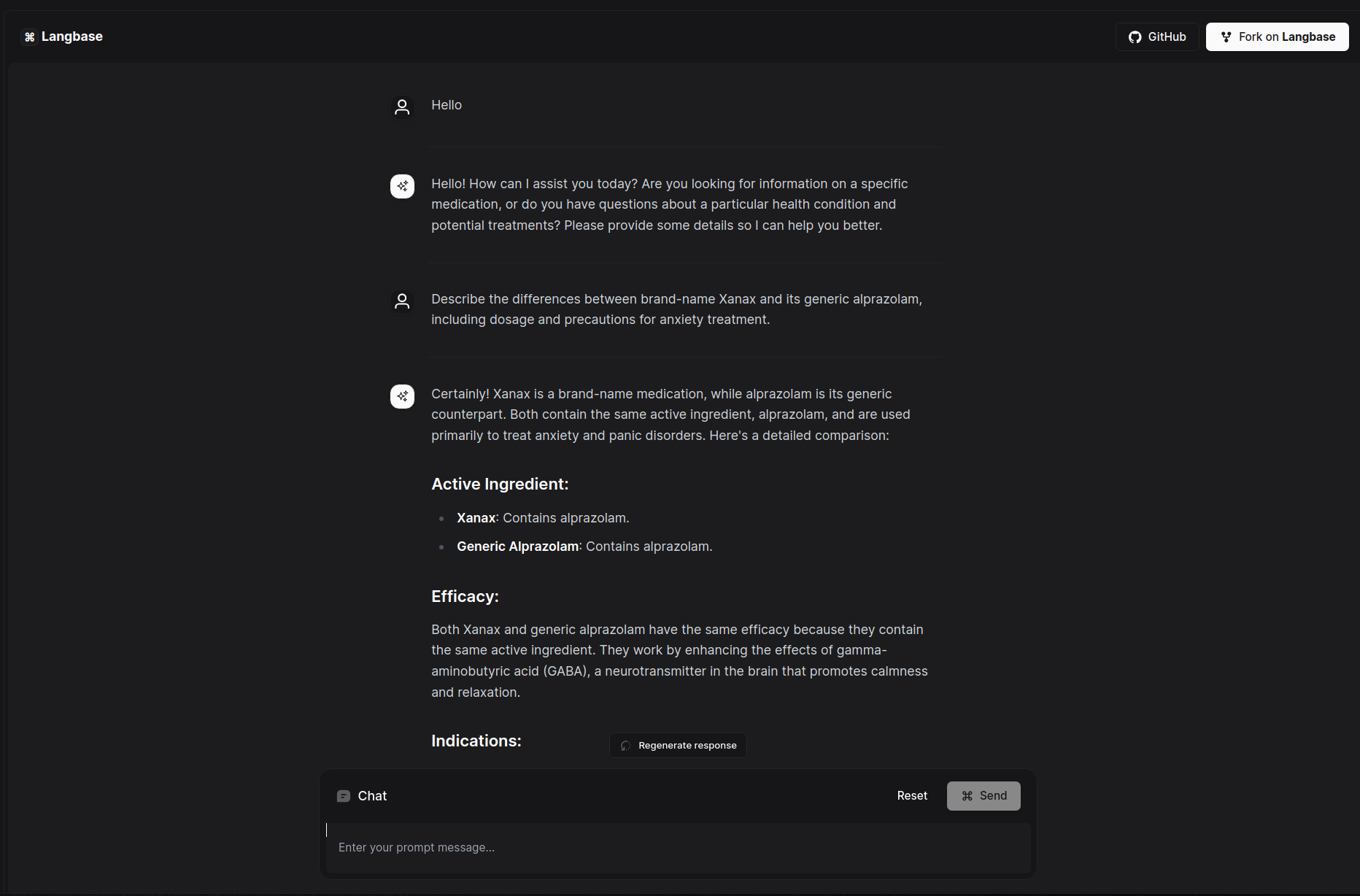
## AI Drug Assistant
This example uses a [chatbot](https://langbase.com/examples/ai-drug-assistant) Pipe on Langbase to create AI Drug Assistant, provides you with comprehensive details on medications, including main ingredients, pharmacological principles, efficacy, indications, dosage, and administration. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://ai-drug-assistant.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/ai-drug-assistant) to see how easy it is to build an app using Pipe and Chat UI. To use AI Drug Assistant
you can use you the following text as an example:
```
You: Hello
AI Drug Assistant: ...
You: Explain how to properly store and administer insulin, including potential interactions with other medications
```
---
## AI Drug Assistant
This example uses a [chatbot](https://langbase.com/examples/ai-drug-assistant) Pipe on Langbase to create AI Drug Assistant, provides you with comprehensive details on medications, including main ingredients, pharmacological principles, efficacy, indications, dosage, and administration. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://ai-drug-assistant.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/ai-drug-assistant) to see how easy it is to build an app using Pipe and Chat UI. To use AI Drug Assistant
you can use you the following text as an example:
```
You: Hello
AI Drug Assistant: ...
You: Explain how to properly store and administer insulin, including potential interactions with other medications
```
 ---
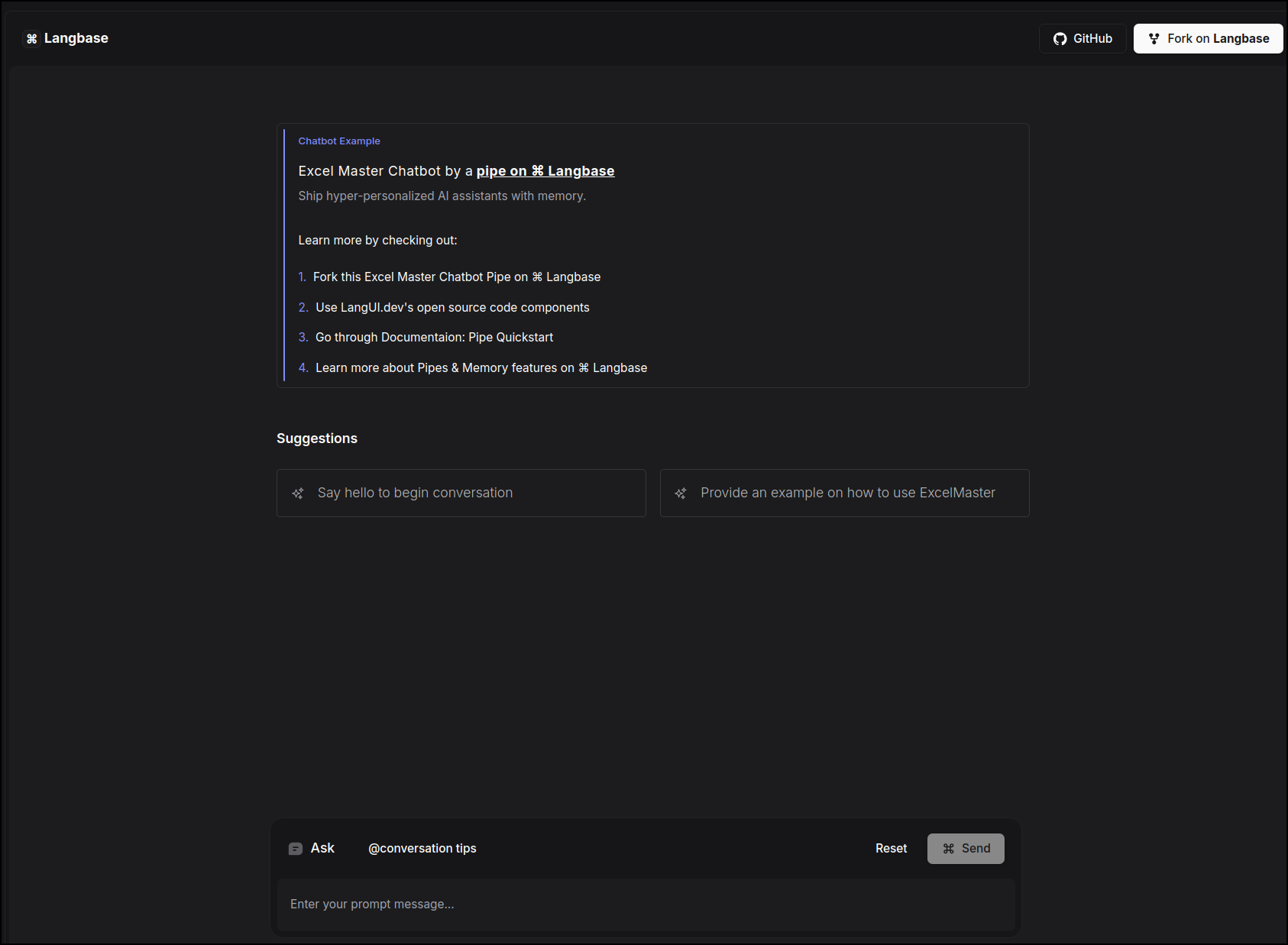
## Excel Master Chatbot
This example uses a [chatbot](https://langbase.com/examples/excel-master) Pipe on Langbase to create Excel Master, providing assistance with Excel tasks including requirement analysis, formula generation, component explanation, implementation guidance, and troubleshooting. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://excel-master.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/excel-master) to see how easy it is to build an app using Pipe and Chat UI. To use the Excel Master chatbot, you can select one of the suggestions presented in the menu.
---
## Excel Master Chatbot
This example uses a [chatbot](https://langbase.com/examples/excel-master) Pipe on Langbase to create Excel Master, providing assistance with Excel tasks including requirement analysis, formula generation, component explanation, implementation guidance, and troubleshooting. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://excel-master.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/excel-master) to see how easy it is to build an app using Pipe and Chat UI. To use the Excel Master chatbot, you can select one of the suggestions presented in the menu.
 ---
## Pseudocode Generator Chatbot
This example uses a [chatbot](https://langbase.com/examples/pseudocode-generator) Pipe on Langbase to create Pseudocode Generator chatbot, offering features like requirement analysis, structured pseudocode generation, data structure explanation, step-by-step comments, time complexity analysis, and reasoning behind the algorithm. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://pseudocode-generator.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/pseudocode-generator) to see how easy it is to build an app using Pipe and Chat UI. To use the Pseudocode Generator, you can select one of the suggestions presented in the menu.
---
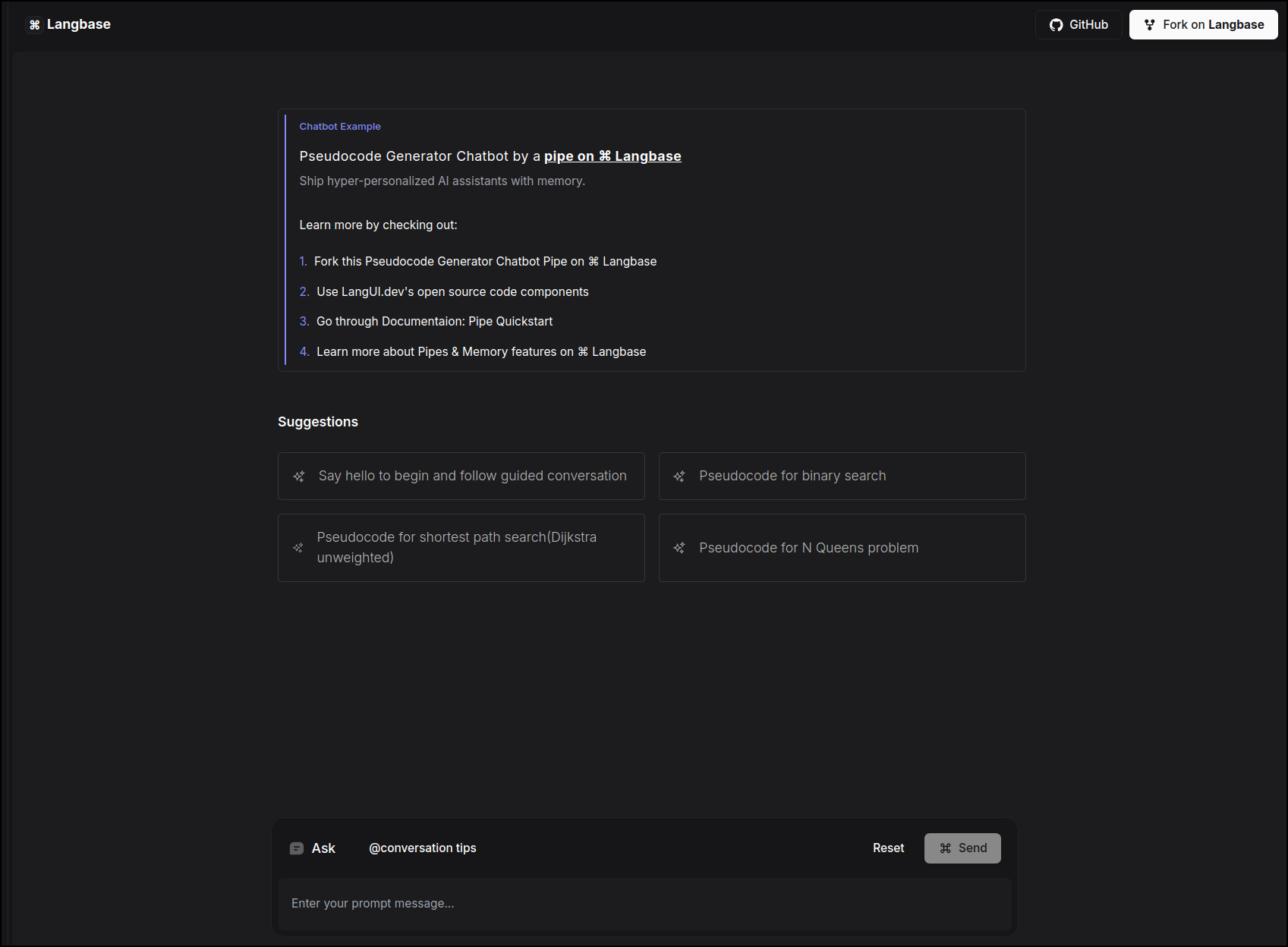
## Pseudocode Generator Chatbot
This example uses a [chatbot](https://langbase.com/examples/pseudocode-generator) Pipe on Langbase to create Pseudocode Generator chatbot, offering features like requirement analysis, structured pseudocode generation, data structure explanation, step-by-step comments, time complexity analysis, and reasoning behind the algorithm. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://pseudocode-generator.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/pseudocode-generator) to see how easy it is to build an app using Pipe and Chat UI. To use the Pseudocode Generator, you can select one of the suggestions presented in the menu.
 ---
## Product Review Generator Chatbot
This example uses a [chatbot](https://langbase.com/examples/product-review-generator) Pipe on Langbase to create Product Review Generator, featuring review crafting, user satisfaction assessment, targeted inquiry, balanced overviews, and consumer insight to generate concise and helpful product reviews based on user feedback. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://product-review-generator.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/product-review-generator) to see how easy it is to build an app using Pipe and Chat UI. To use this chatbot, you can select one of the suggestions presented in the menu. See conversation tips to get the best results.
---
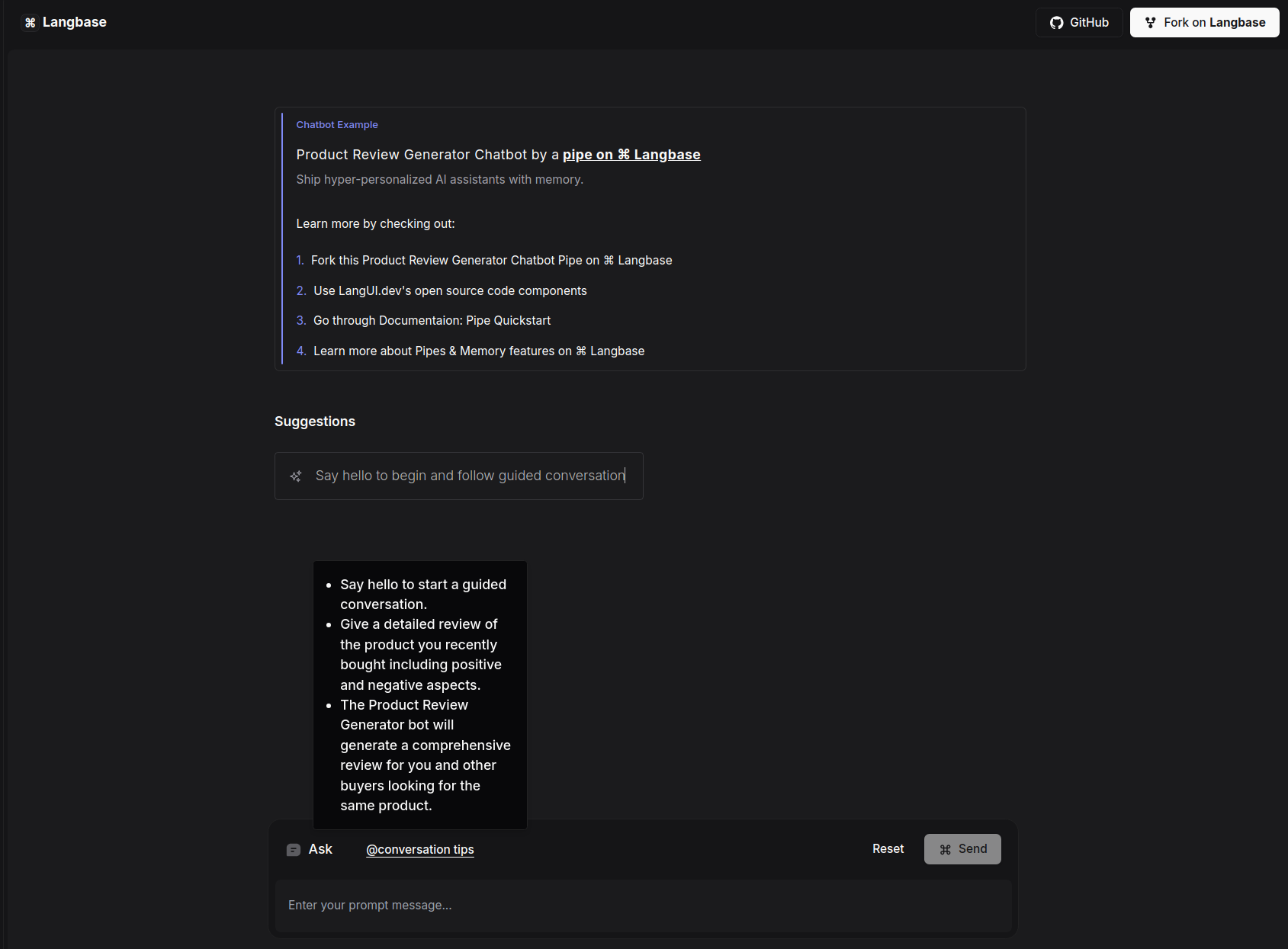
## Product Review Generator Chatbot
This example uses a [chatbot](https://langbase.com/examples/product-review-generator) Pipe on Langbase to create Product Review Generator, featuring review crafting, user satisfaction assessment, targeted inquiry, balanced overviews, and consumer insight to generate concise and helpful product reviews based on user feedback. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://product-review-generator.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/product-review-generator) to see how easy it is to build an app using Pipe and Chat UI. To use this chatbot, you can select one of the suggestions presented in the menu. See conversation tips to get the best results.
 ---
## Dev Screener Chatbot
This example uses a [chatbot](https://langbase.com/examples/dev-screener) Pipe on Langbase to create Dev Screener, which enhances the candidate experience through personalized interviews and optimizes the talent pool by systematically evaluating and categorizing applicants for efficient HR decision-making. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://dev-screener.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/dev-screener) to see how easy it is to build an app using Pipe and Chat UI. To use this chatbot, select a suggestion from the menu to start a guided conversation. See the conversation tips to get the best results.
---
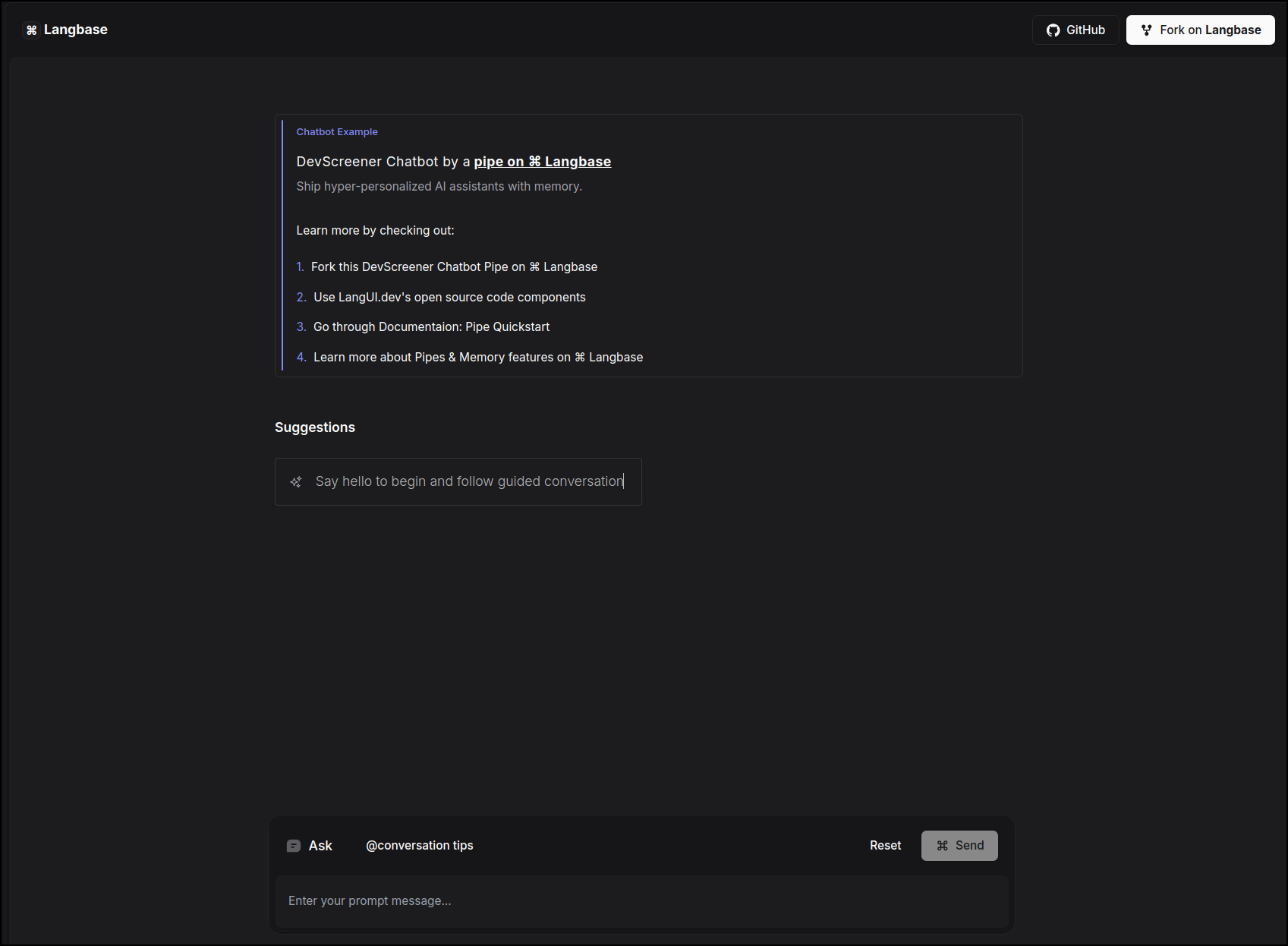
## Dev Screener Chatbot
This example uses a [chatbot](https://langbase.com/examples/dev-screener) Pipe on Langbase to create Dev Screener, which enhances the candidate experience through personalized interviews and optimizes the talent pool by systematically evaluating and categorizing applicants for efficient HR decision-making. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://dev-screener.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/dev-screener) to see how easy it is to build an app using Pipe and Chat UI. To use this chatbot, select a suggestion from the menu to start a guided conversation. See the conversation tips to get the best results.
 ---
## API Security Consultant Chatbot based on OWASP 2023
This example uses a [chatbot](https://langbase.com/examples/api-sec-consultant) Pipe on Langbase to create API Security Consultant, which guides users through a comprehensive OWASP 2023-based API security assessment via a structured MCQ process that evaluates vulnerabilities, educates developers, and ensures compliance. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://api-sec-consultant.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/api-sec-consultant) to see how easy it is to build an app using Pipe and Chat UI. To use this Chatbot, select a suggestion from the menu to start a guided conversation. See conversation tips to get the best.
---
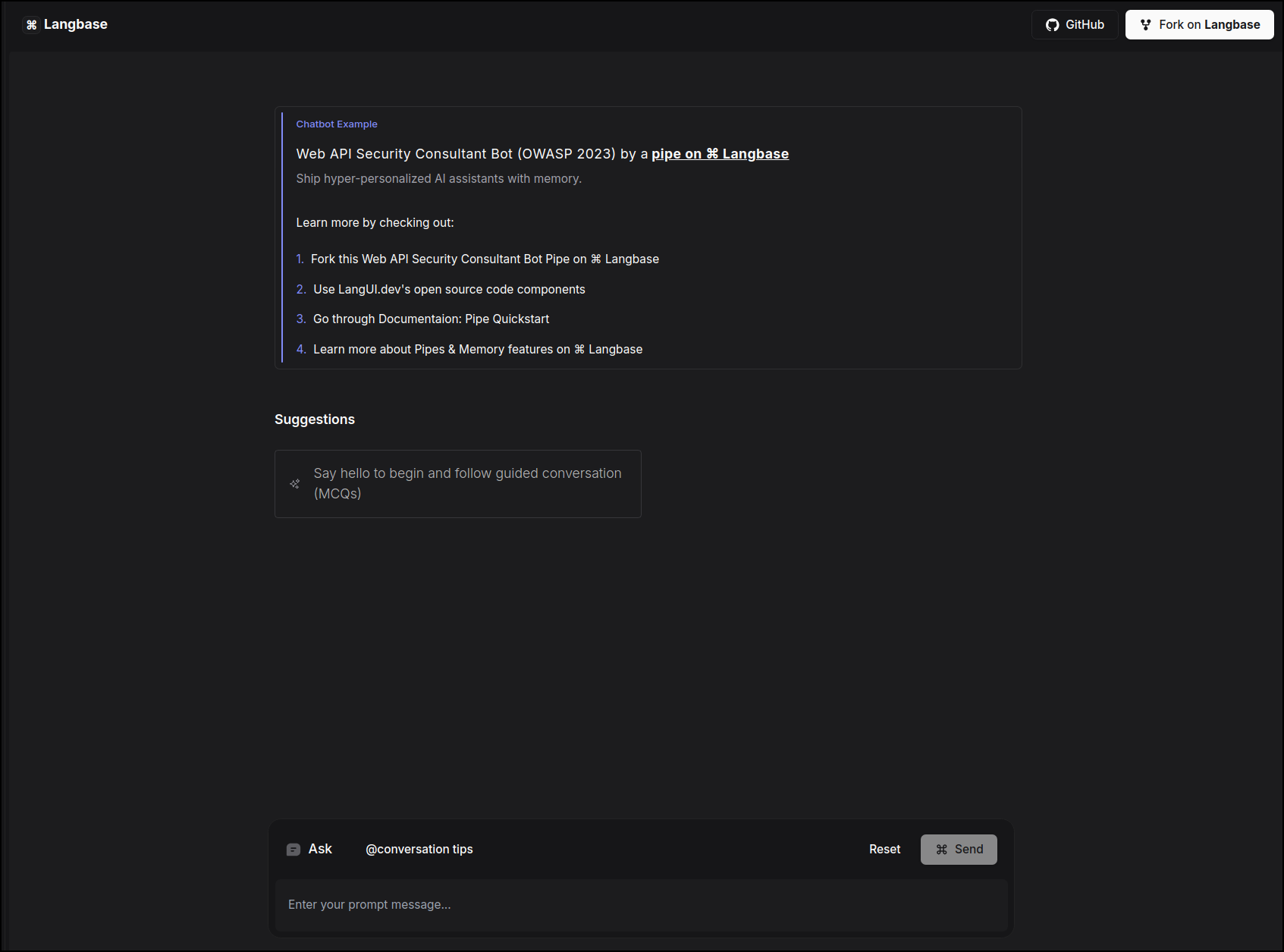
## API Security Consultant Chatbot based on OWASP 2023
This example uses a [chatbot](https://langbase.com/examples/api-sec-consultant) Pipe on Langbase to create API Security Consultant, which guides users through a comprehensive OWASP 2023-based API security assessment via a structured MCQ process that evaluates vulnerabilities, educates developers, and ensures compliance. It uses the Pipe `chat` API.
Since the app uses a [Pipe](/pipe), we can easily **switch** to any LLM model from the extensive list of [providers](/supported-models-and-providers) on Langbase. You can customize the prompt of the pipe, and the chatbot will respond accordingly.
[Try out](https://api-sec-consultant.langbase.dev/) the example and take a look at the [source code](https://github.com/LangbaseInc/langbase/tree/main/examples/api-sec-consultant) to see how easy it is to build an app using Pipe and Chat UI. To use this Chatbot, select a suggestion from the menu to start a guided conversation. See conversation tips to get the best.
 ---
---
Enter a topic and click the button to generate titles using LLM
setTopic(e.target.value)} /> {loading &&Loading...
} {completion && (Enter a topic and click the button to generate titles using LLM
setTopic(e.target.value)} /> {loading &&Loading...
} {completion && (Enter a topic and click the button to generate titles using LLM
setTopic(e.target.value)} /> {loading &&Loading...
} {completion && (Completion: {completion}
)}Enter a topic and click the button to generate titles using LLM
setTopic(e.target.value)} /> {loading &&Loading...
} {completion && (Completion: {completion}
)} The Vision model will process the image and generate a text-based response like this.
```
The image depicts an iridescent green sweat bee, likely of the genus Agapostemon or Augochlorini.
In the image, the bee is perched on a flower, likely foraging for nectar or pollen, which is a common behavior for these pollinators.
```
---
## How to use Vision in Langbase Pipes?
Vision is supported in Langbase Pipes across different LLM providers, including OpenAI, Anthropic, Google, and more. Using Vision in Langbase Pipes is simple. You can send images in the API request and get text answers about them.
## Sending Images to Pipe for Vision
First, select a Vision model that supports image input in your [Langbase Pipe](/pipe). You can choose from a variety of Vision models from different LLM providers. For example, OpenAI's `gpt-4o` or Anthropic's `claude-3.5-sonnet`.
The Pipe Run API matches the [OpenAI spec](https://platform.openai.com/docs/guides/vision) for Vision requests. When running the pipe, provide the image in a message inside the `messages` array.
Here is what your messages will look like for vision requests:
```ts
// Pipe Run API
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is in this image?"
}
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,iVBOR...xyz" // base64 encoded image
}
}
]
}
]
```
In the above example, we are sending an image URL (base64 encoded image) as input to the vision model pipe, which will process the image and give a text response.
Follow the [Run Pipe API spec](/api-reference/pipe/run) for detailed request types.
### Image Input Guidelines for Vision
Here are some considerations when using vision in Langbase Pipes:
1. **Message Format**
- Images can be passed in `user` role messages.
- Message `content` must be an array of content parts (for text and images) in vision requests. While in text-only requests, the message `content` is a string.
2. **Image URL**
- The `image_url` field is used to pass the image URL, which can be:
1. **Base64 encoded images**: Supported by all providers.
2. **Public URLs** Supported only by OpenAI.
3. **Provider-specific limits**
- Different LLM providers may impose varying restrictions on image size, format, and the number of images per request.
- Refer to the specific provider’s documentation for precise limits.
- Langbase imposes no additional restrictions.
4. **Image Quality Settings** (OpenAI only)
- OpenAI models support an optional detail field in the image_url object for controlling image quality.
- The `detail` field can be set to `low`, `medium`, or `high` to control the quality of the image sent to the model.
## Examples
Here are some example Pipe Run requests utilizing Vision models in Langbase Pipes.
### Example 1: Sending a Base64 Image
Here is an example of sending a base64 image in a Pipe Run API request.
```bash
curl https://api.langbase.com/v1/pipes/run \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer
The Vision model will process the image and generate a text-based response like this.
```
The image depicts an iridescent green sweat bee, likely of the genus Agapostemon or Augochlorini.
In the image, the bee is perched on a flower, likely foraging for nectar or pollen, which is a common behavior for these pollinators.
```
---
## How to use Vision in Langbase Pipes?
Vision is supported in Langbase Pipes across different LLM providers, including OpenAI, Anthropic, Google, and more. Using Vision in Langbase Pipes is simple. You can send images in the API request and get text answers about them.
## Sending Images to Pipe for Vision
First, select a Vision model that supports image input in your [Langbase Pipe](/pipe). You can choose from a variety of Vision models from different LLM providers. For example, OpenAI's `gpt-4o` or Anthropic's `claude-3.5-sonnet`.
The Pipe Run API matches the [OpenAI spec](https://platform.openai.com/docs/guides/vision) for Vision requests. When running the pipe, provide the image in a message inside the `messages` array.
Here is what your messages will look like for vision requests:
```ts
// Pipe Run API
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is in this image?"
}
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,iVBOR...xyz" // base64 encoded image
}
}
]
}
]
```
In the above example, we are sending an image URL (base64 encoded image) as input to the vision model pipe, which will process the image and give a text response.
Follow the [Run Pipe API spec](/api-reference/pipe/run) for detailed request types.
### Image Input Guidelines for Vision
Here are some considerations when using vision in Langbase Pipes:
1. **Message Format**
- Images can be passed in `user` role messages.
- Message `content` must be an array of content parts (for text and images) in vision requests. While in text-only requests, the message `content` is a string.
2. **Image URL**
- The `image_url` field is used to pass the image URL, which can be:
1. **Base64 encoded images**: Supported by all providers.
2. **Public URLs** Supported only by OpenAI.
3. **Provider-specific limits**
- Different LLM providers may impose varying restrictions on image size, format, and the number of images per request.
- Refer to the specific provider’s documentation for precise limits.
- Langbase imposes no additional restrictions.
4. **Image Quality Settings** (OpenAI only)
- OpenAI models support an optional detail field in the image_url object for controlling image quality.
- The `detail` field can be set to `low`, `medium`, or `high` to control the quality of the image sent to the model.
## Examples
Here are some example Pipe Run requests utilizing Vision models in Langbase Pipes.
### Example 1: Sending a Base64 Image
Here is an example of sending a base64 image in a Pipe Run API request.
```bash
curl https://api.langbase.com/v1/pipes/run \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer